 November 6, 2025
November 6, 2025
原文链接:The Green Tea Garbage Collector
Go 1.25 引入了一款名为 Green Tea 的新型实验性垃圾回收器,在构建时通过设置 GOEXPERIMENT=greenteagc 来启用。
许多工作负载在垃圾回收上花费的时间减少了约 10%,但有些工作负载的降幅高达 40%!它已经为生产环境做好了准备,并且已经在 Google 内部使用,我们鼓励您尝试一下。我们知道有些工作负载受益不多,甚至根本没有受益,因此您的反馈对于我们未来的工作至关重要。
根据我们现在掌握的数据,我们计划在 Go 1.26 中将其作为默认设置。要报告任何问题,请提交一个新 issue。要报告任何成功案例,请回复现有的 Green Tea issue。
本文是根据 Michael Knyszek 在 GopherCon 2025 上的演讲整理而成的博客文章。一旦演讲视频在线发布,我们将更新这篇博文并附上链接。
理解垃圾回收
#
在我们讨论 Green Tea 之前,让我们先就垃圾回收达成共识。
对象和指针
#
垃圾回收的目的是自动回收和重用程序不再使用的内存。为此,Go 垃圾回收器关注的是 对象 和 指针。
在 Go 运行时的上下文中,对象是其底层内存在堆上分配的 Go 值。当 Go 编译器无法确定值的生命周期时,就会在堆上分配内存。例如,以下代码片段分配了一个堆对象:一个指针切片的底层存储空间。
var x = make([]*int, 10) // 全局变量
Go 编译器无法将切片底层存储分配在堆以外的任何地方,因为它很难知道(甚至不可能知道) x 会引用该对象多长时间。
指针只是指示 Go 值在内存中位置的数字,Go 程序就是通过指针来引用对象的。例如,要获取上一个代码片段中分配的对象的起始地址的指针,我们可以这样写:
标记清除
#
Go 的垃圾回收器遵循一种广义上称为追踪式垃圾回收的策略,这意味着垃圾回收器会跟随或“追踪”程序中的指针,以确定程序仍在使用的对象。
...
February 26, 2024
NATS设计与实现
#
https://github.com/nats-io/nats-sevrer
NATS 就是一个消息中间件,提供了 Pub/Sub 核心数据流,并基于此构建了 Request/Reply API 和 JetStream 用来提供可靠的分布式存储能力,和更高的 QoS(至少一次 + ACK)。
 ...
...
October 10, 2023
本文如果没有特殊说明,所有的内容都是指 linux 系统
起因是从 kratos 群里看到有人问:“测了下kratos的config watch,好像对软链不生效”,他提供的屏幕截图如下类似:
$ pwd
/tmp/testconfig
$ ls -l
drwxr-xr-x 3 root root 4096 Oct 10 19:48 .
drwxr-xr-x 10 root root 4096 Oct 10 19:48 ..
drwxr-xr-x 1 root root 11 Oct 10 19:48 ..ver1
drwxr-xr-x 1 root root 11 Oct 10 19:48 ..ver2
lrwxr-xr-x 1 root root 11 Oct 10 19:48 ..data -> ..ver1
drwxr-xr-x 1 root root 11 Oct 10 19:48 data
$
$ ll -a data
drwxr-xr-x 3 root root 4096 Oct 10 19:48 .
drwxr-xr-x 10 root root 4096 Oct 10 19:48 ..
lrwxrwxrwx 1 root root 11 Oct 10 19:48 registry.yaml -> /tmp/testconfig/..data/registry.yaml
然后触发更新的动作其实是把 ..data 的源改成了 ..ver2,但是发现并没有触发更新,于是就问了一下。
...
August 17, 2023
假设我们有一个长连接服务,我们想要对它进行升级,但是不想让客户端受到影响应该怎么做?这个问题其实是一个很常见的问题,比如我们的游戏服务器,我们的 IM 服务器,推送服务器等等,诸如此类使用tcp长连接的服务,都会遇到这个问题。那么我们应该怎么做呢?
需求分析
#
我们可以先来看下这个场景下的需求:
- 客户端必须要对这个操作没有感知,也就是说客户端不需要做任何的修改,在服务器升级的过程中不需要配合。
- 服务器在升级的过程中,不能丢失任何的连接,也就是说,如果有新的连接进来,那么这个连接必须要被接受,如果有旧的连接,那么客户端不能够触发重连。
基本思路
#
实现思路的讨论范围限制在 linux 服务器上
为了实现上述的要求,首先在升级流程中我们需要做到以下几点:
- 旧的服务器进程在处理完请求前不能退出,而且一旦升级开始就不能再接受新的连接。
- 旧的服务器进程在所有连接都处理完毕后才能退出。
- 新的服务器进程在启动时需要继承旧的服务器进程的所有连接,新的连接也应该被新的服务器进程接受。
- 新的服务器进程也必须监听旧的服务器进程的监听端口,否则新的连接无法被接受。
那么通过 Google 和 ChatGPT 的帮助,我们可以找到一些思路:
新进程继承旧进程的(监听)套接字,而不是创建新的。
为什么不创建新的(监听)套接字呢?在 linux 中内核会把处在不同握手阶段的TCP连接放在不同的队列中(半连接/全连接)。服务器的监听套接字会有自己的队列,如果创建新的套接字,那么旧的套接字队列中的连接就会丢失。为了做到客户端无感知,我们需要继承旧的套接字(主要是为了连接队列中的连接不丢失)。
半连接队列:当客户端发送 SYN 包时,服务器会把这个连接放在半连接队列中,等待服务器的 ACK 包,这个时候连接处于半连接状态。当服务器发送 ACK 包时,这个连接就会从半连接队列中移除,放到全连接队列中,这个时候连接处于全连接状态。当服务器调用 accept 时,就会从全连接队列中取出一个连接,这个时候连接处于 ESTABLISHED 状态。
实现方式
#
那么在 linux 中,我们可以通过以如下方式实现:
- 通过
fork 创建子进程,子进程继承父进程的所有资源,包括监听套接字;
- 子进程通过
exec 加载最新的二进制程序执行,这样就实现了新进程继承旧进程的监听套接字。
- 新进程启动完成后,通知父进程退出。
- 父进程受到信号后,停止接受新的连接,等待所有的连接处理完毕后退出。
在 Go 里面,我们可以通过如下方式实现:
type gracefulTcpServer struct {
listener *net.TCPListener
shutdownChan chan struct{}
conns map[net.Conn]struct{}
servingConnCount atomic.Int32
serveRunning atomic.Bool
}
// 普通启动方式
func start(port int) (*gracefulTcpServer, error) {
ln, err := net.Listen("tcp", fmt.Sprintf(":%d", port))
// handle error ignored
s := &gracefulTcpServer{
listener: ln.(*net.TCPListener),
shutdownChan: make(chan struct{}, 1),
conns: make(map[net.Conn]struct{}, 16),
servingConnCount: atomic.Int32{},
serveRunning: atomic.Bool{},
}
return s, nil
}
// 优雅重启启动方式
func startFromFork() (*gracefulTcpServer, error) {
// ... ignored code
// 从环境变量中获取 父进程的处理的连接数,用来恢复连接
if nfdStr := os.Getenv(__GRACE_ENV_NFDS); nfdStr == "" {
panic("not nfds env")
} else if nfd, err = strconv.Atoi(nfdStr); err != nil {
panic(err)
}
// restore conn fds, 0, 1, 2 has been used by os.Stdin, os.Stdout, os.Stderr
lfd := os.NewFile(3, filepath.Join(tmpdir, "graceful"))
ln, err := net.FileListener(lfd)
// handle error ignored
s := &gracefulTcpServer{
listener: ln.(*net.TCPListener),
shutdownChan: make(chan struct{}, 1),
conns: make(map[net.Conn]struct{}, 16),
servingConnCount: atomic.Int32{},
serveRunning: atomic.Bool{},
}
// 从父进程继承的套接字中恢复连接
for i := 0; i < nfd; i++ {
fd := os.NewFile(uintptr(4+i), filepath.Join(tmpdir, strconv.Itoa(4+i)))
conn, err := net.FileConn(fd)
// handle error ignored
go s.handleConn(conn)
}
return s, nil
}
func (s *gracefulTcpServer) gracefulRestart() {
_ = s.listener.SetDeadline(time.Now())
lfd, err := s.listener.File()
// 给子进程设置 优雅重启 相关的环境变量
os.Setenv(__GRACE_ENV_FLAG, "true")
os.Setenv(__GRACE_ENV_NFDS, strconv.Itoa(len(s.conns)))
// 将父进程的监听套接字传递给子进程
files := make([]uintptr, 4, 3+1+len(s.conns))
copy(files[:4], []uintptr{
os.Stdin.Fd(),
os.Stdout.Fd(),
os.Stderr.Fd(),
lfd.Fd(),
})
// 将父进程的套接字传递给子进程
for conn := range s.conns {
connFd, _ := conn.(*net.TCPConn).File()
files = append(files, connFd.Fd())
}
procAttr := &syscall.ProcAttr{
Env: os.Environ(),
Files: files,
Sys: nil,
}
// 执行 fork + exec 调用
childPid, err := syscall.ForkExec(os.Args[0], os.Args, procAttr)
}
func main() {
// ...
// 根据环境变量判断是 fork 还是新启动
if v := os.Getenv(__GRACE_ENV_FLAG); v != "" {
s, err = startFromFork()
} else {
s, err = start(*port)
}
go s.serve()
// 处理信号,如果是 SIGHUP 信号,则执行 gracefulRestart 方法后再退出
s.waitForSignals()
}
完整代码可以在 https://github.com/yeqown/playground/golang/tcp-graceful-restart 中找到。
...
July 25, 2022
背景
#
最近在为 大仓项目(Monorepo) 制作一个脚手架,其中构思了一个自动替用户切换工作路径的工具(代码是通过模板初始化的,在结构上基本一致,但是代码文件较深,想要在terminal去和文件交互时,只能使用 cd 命令,费时费力),因此我期望一个小工具,能比较方便的帮我跳转到目标路径。预期的使用效果如下:
这个命令执行后,你可以从当前路径(任意路径)跳转到目标路径,那我就不用记我应该先跳转到根目录再前往目标目录了,少敲击很多次 tab。
PS: 后续计划给这个命令扩展一下历史记录,可以通过筛选匹配历史快速补全命令,提高效率。
chdir没作用?
#
这个小工具是通过Go来编写的,我从文档中看到 os.Chdir 这个调用, 因此用它来试试:
// Chdir changes the current working directory to the named directory.
// If there is an error, it will be of type *PathError.
func Chdir(dir string) error
结果我发现没有效果,通过 os.Getwd() 却能看到当前路径已经被改变了。这个切换的需求还没解决,我却产生了几个新的疑问:
cd 命令怎么实现的?chdir 系统调用的使用和原理?
通过执行如下的命令,会发现 cd 命令并不是通过一个独立的可执行文件来实现的,而是内置在 bash 等 shell 程序中,其次通过查阅资料可以发现
大部分Linux发行版都部分符合 POSIX 标准。如果再检索一下shell程序的原理,我们会得出如下的结论:
$ which cd
cd: shell built-in command
shell 程序在执行内建命令时,是通过调用内部的函数的执行。而非内建的命令(如 git / gcc / gdb)都是通过 fork 一个进程来执行;cd 命令是通过 chdir [IEEE Std 1003.1-1988] 系统调用实现的;chdir 在 <uinstd.h> 头文件中定义;
...
January 27, 2022
需求和背景分析
#
一提到定时任务的使用场景,我们肯定能想到很多场景,比如:
- 每天晚上12点执行一次清理数据的任务
- 每天凌晨1点给符合条件的用户发送推广邮件
- 每个月10号结算工资
- 每隔5分钟检查一次服务器的状态
- 每天根据用户的配置,给用户发送站内消息提醒
- …
从常见的场景中,我们可以提炼出一些定时任务的特点:
| 序号 |
特点 |
说明 |
| 1 |
定时 |
执行时间有规则 |
| 2 |
可靠 |
可以延迟执行,但不能不执行;可以不执行,但是不能多执行 |
| 3 |
并发(可能) |
某些场景下,可以运行多个 cron 进程来提高执行效率 |
| 4 |
可执行 |
这个有点废话了,但是这个关系到 cronjob 的设计,因此在这里还是提出来 |
但是作为一个系统来说,我们需要更多的功能来提升用户体验,保证平台的可靠和稳定。我们设想下以下的场景:
- 定时任务已经触发了,但是有没有执行,执行结果是什么?
- 如果一个定时任务长时间运行,那么它正常吗?
- 一个定时任务还在运行,但是下一个触发时机又到来了,该怎么办?
- 如果服务器资源已经处于高位,那么要被触发的任务还触发吗?
- …
最后,基本的访问控制,权限分配和API设计,这些都是系统功能的一部分,但不作为本文的重点考虑对象。
一些概念
#
到这里我们可以提取一些概念,来帮助我们设计一个系统:
| 序号 |
名词 |
解释 |
| 1 |
CronJob |
定时任务实例,描述定时任务资源的一个实体 |
| 2 |
Job |
执行中的定时任务 |
| 3 |
Scheduler |
调度器,负责触发 CronJob 执行和监控 Job 的执行状态;或许还会存储一些 CronJob 的状态 |
| 4 |
JobRuntime |
job 运行时,准备 Job 运行时需要的资源; 可以参考 k8s CRI |
这里 JobRuntime 是抽象化的概念,因为 Job 可以是k8s上的POD,也可以是物理机的进程,还可以是一个进程中的coroutine。
...
January 25, 2022
背景
#
gRPC 作为服务端的常用框架,它通过 protocol-buffers 语言来定义服务,同时也约定了请求和响应的格式,这样在服务端和客户端之间就可以通过 protoc 生成的代码直接运行而不用考虑编码传输问题了。
但是,可能会遇到这样的场景:
-
RPC 响应中 无用的字段过多 , 浪费带宽和无效计算,如下图所示:
这里的无用字段是指,在响应中,没有用到的字段,这些字段可以忽略掉,不会影响客户端的使用。
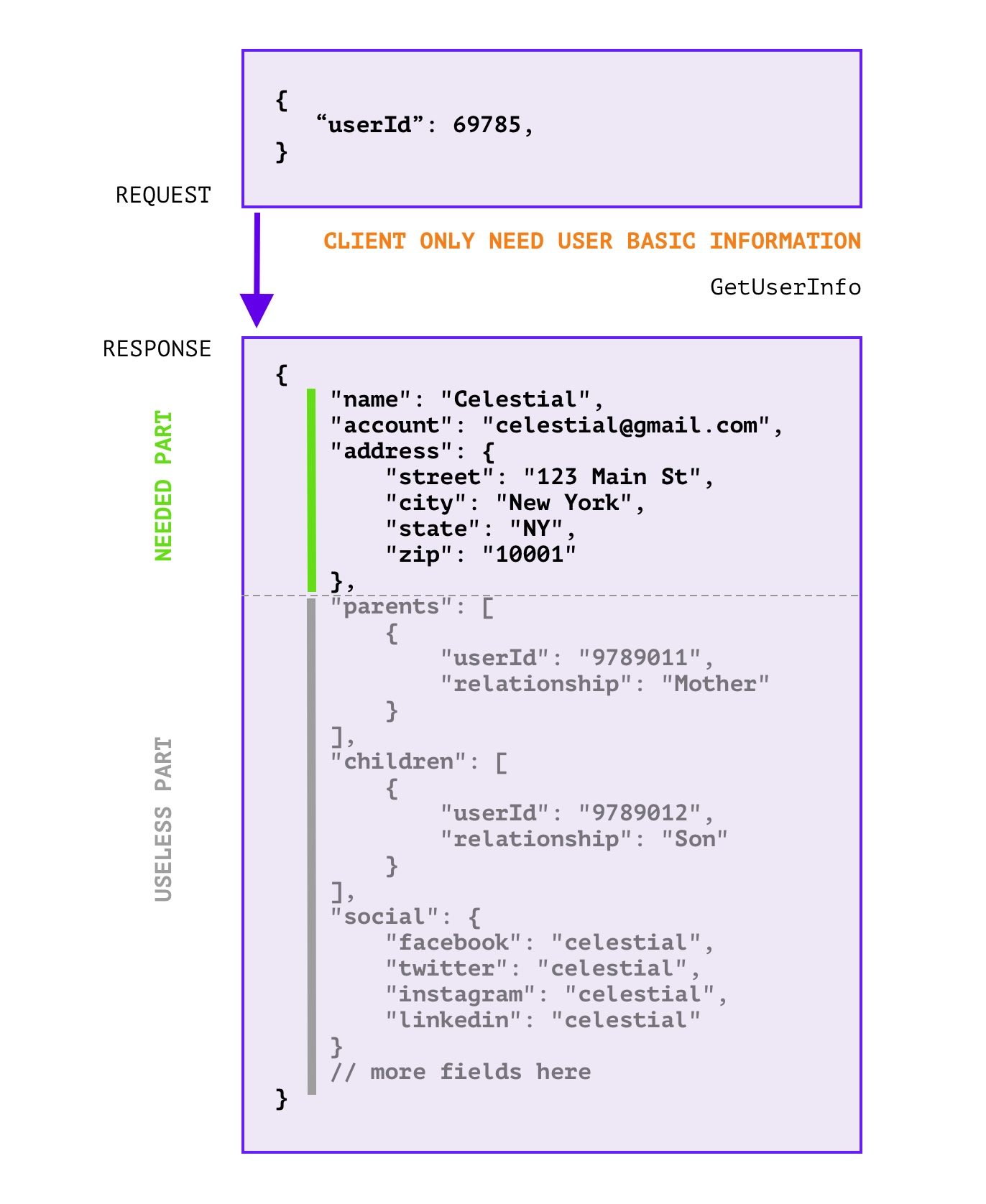
或许 拆分接口 是一个好的办法,但是可能会因为这样那样的原因(信息粒度降低导致接口太多了,有些地方就是需要聚合信息;细粒度的API设计同时会导致代码重复增加),可能无法推动拆分改造。同时如果没有拆分标准,亦或团队内成员不能严格遵守标准,那么拆分也只是重复问题而已。
-
RPC 增量更新时,如何判断零值字段是否需要更新?
对于 unset 和 zero value 不好区分的语言中(比如:go),在提供服务的一方遇到 增量更新 的场景时就会遇到这样的情况:
对于这种情况当然可以也有一些方法来解决,比如:使用指针来定义数据基本类型,那么在使用的时候如果判定为 nil 就说明没有设置,如果不为 nil 且为零值,那么就说明也是需要更新的。不过这样解决的缺点就是,nil refference panic 的概率又增加了,在使用时也稍微麻烦了一点。
 ·
·
解决方案
#
其实我们在思考上述两种场景的时候,把 客户端 和 服务端 的角色提取出来,就会发现这两个场景都是从 服务端 的视角遇到的问题,两个场景都是类似的:
- 客户端需要哪些字段,服务端不知道
- 客户端更新了哪些字段,服务端也不知道
但是,其实客户端是知道的,因此让客户端把这部分信息传递给服务端就行了。因此我们可以用 FieldMask 字段,用来传递客户端需要的字段,服务端就只返回需要的字段;客户端的告诉服务端需要哪些字段,服务端就更新哪些字段。
但是 FieldMask 只是一个定义,在具体的使用场景中还需要开发者自己编写一些辅助方法,来实现功能。那么是不是可以提供一个插件,让开发者可以只编写 proto 文件,便可以自动生成一些辅助方法呢?答案是肯定的,预览效果如下:
message UserInfoRequest {
string user_id = 1;
google.protobuf.FieldMask field_mask = 2 [
(fieldmask.option.Option).in = {gen: true},
(fieldmask.option.Option).out = {gen: true, message:"UserInfoResponse"}
];
}
message Address {
string country = 1;
string province = 2;
}
message UserInfoResponse {
string user_id = 1;
string name = 2;
string email = 3;·
Address address = 4;
}
message NonEmpty {}
service UserInfo {
rpc GetUserInfo(UserInfoRequest) returns (UserInfoResponse) {}
rpc UpdateUserInfo(UserInfoRequest) returns (NonEmpty) {}
}
生成的代码如下:
...
December 15, 2021
自从微服务大行其道,容器化和k8s编排一统天下之后,“可观测性” 便被提出来。这个概念是指,对于应用或者容器的运行状况的掌控程度,其中分为了三个模块:Metrics、Tracing、Logging。Metrics 指应用采集的指标;Tracing 指应用的追踪;Logging 指应用的日志。
日志自不用多说,这是最原始的调试和数据采集能力。Metrics 比较火的方案就是 Prometheus + Grafana,思路就是通过应用内埋入SDK,选择 Pull 或者 Push 的方式将数据收集到 prometheus 中,然后通过 Grafana 实现可视化,当然这不是本文的重点就此略过。
Tracing 也并不是可观测性提出后才诞生的概念,在微服务化的进程中就已经有Google的Dapper落地实践,并慢慢形成 OpenTracing 规范,这一规范又被多家第三方框架所支持,如 Jaeger、Zipkin 等。OpenTelemetry 就是结合了 OpenTracing + OpenCensus 规范,约定并提供完成的可观测性套件,只是目前(2021-12-15)稳定下来的只有 Tracing 这一部分而已。对 OpenTelemetry 发展历史感兴趣的可以自行了解。
效果预览
#
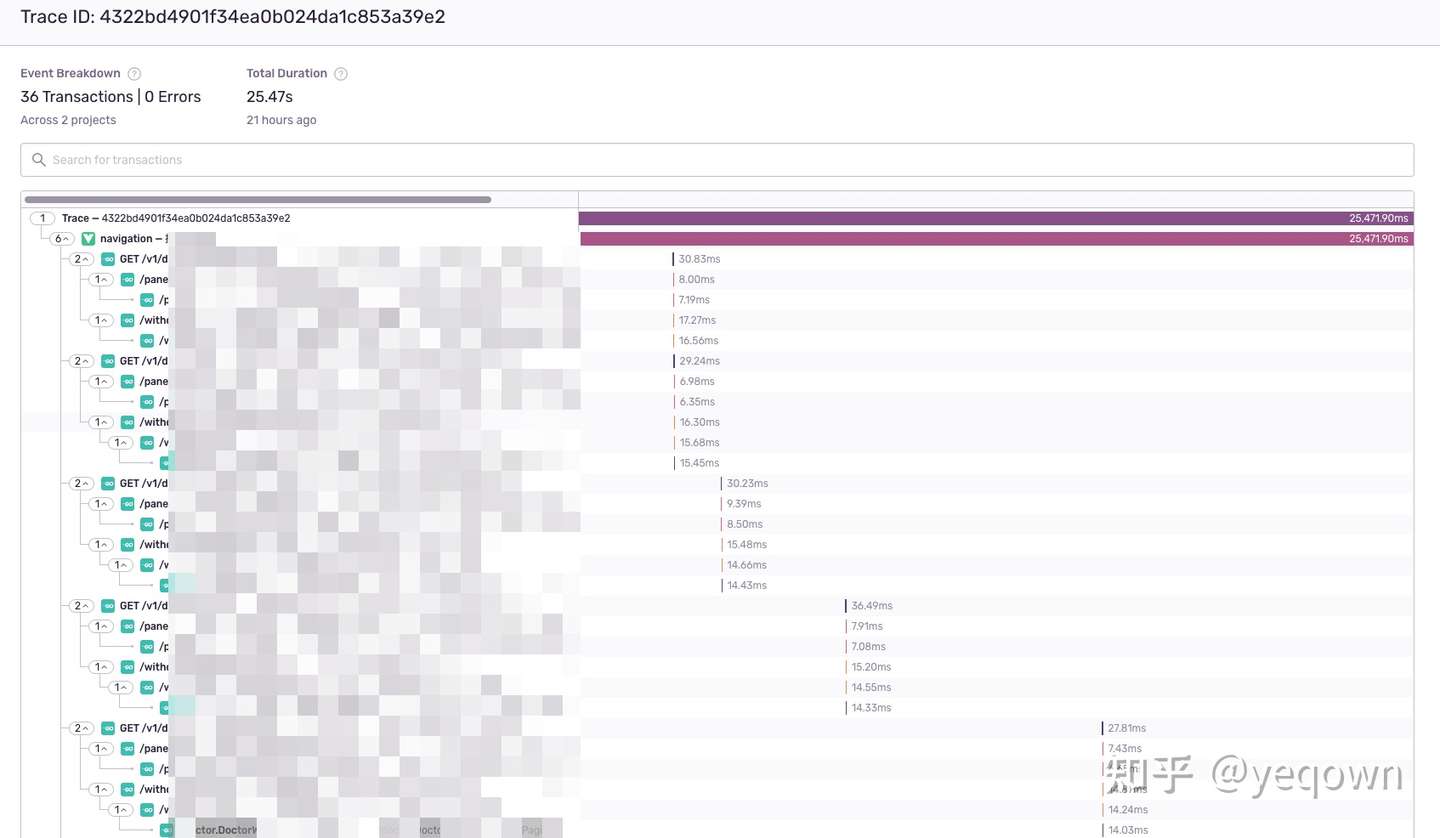
链路总览,包含了前端页面的生命周期 + 整个了链路采集到的Span聚合。
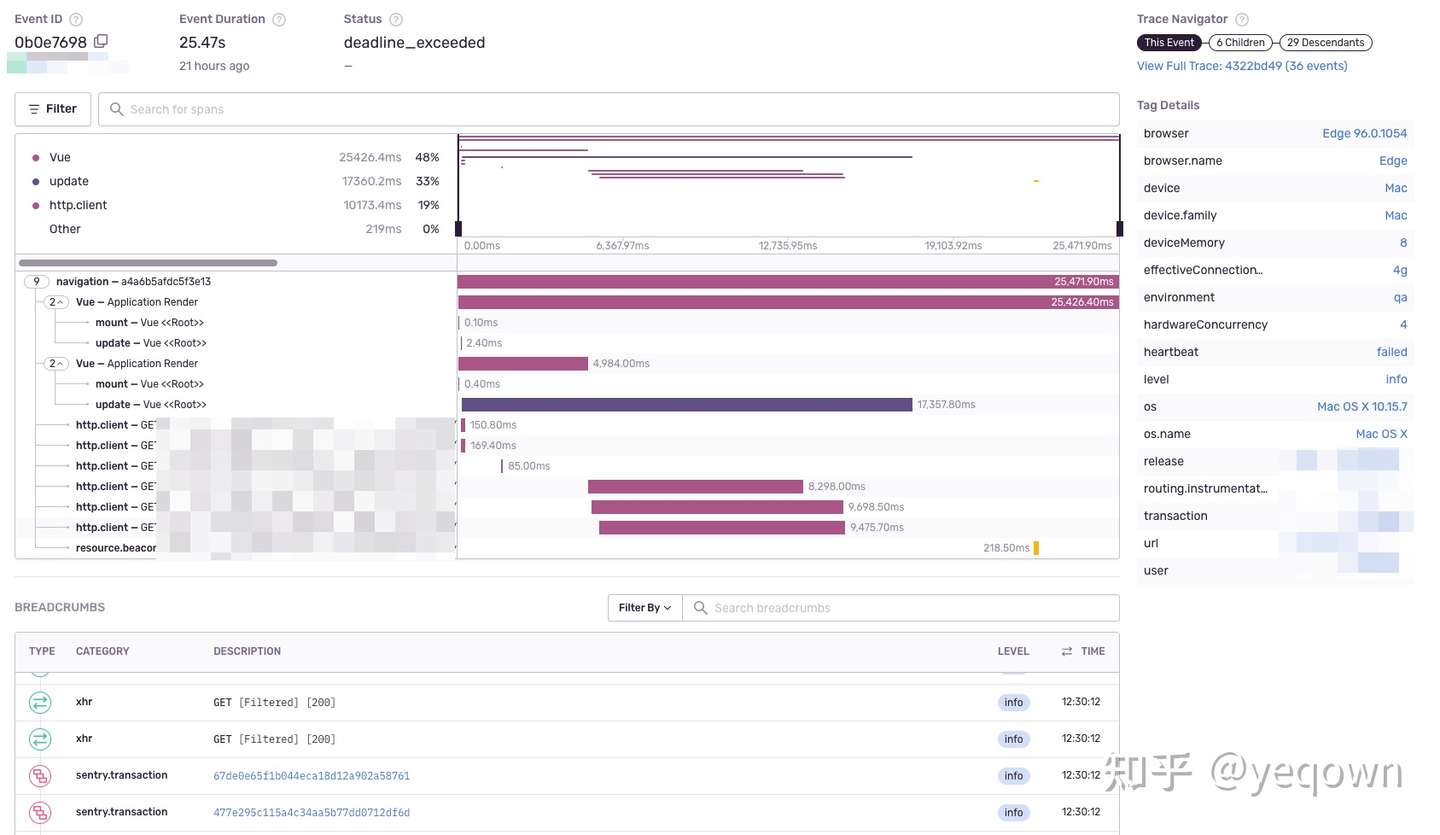
前端页面指标采集概览,包含了该页面生命周期内的动作和日志等。
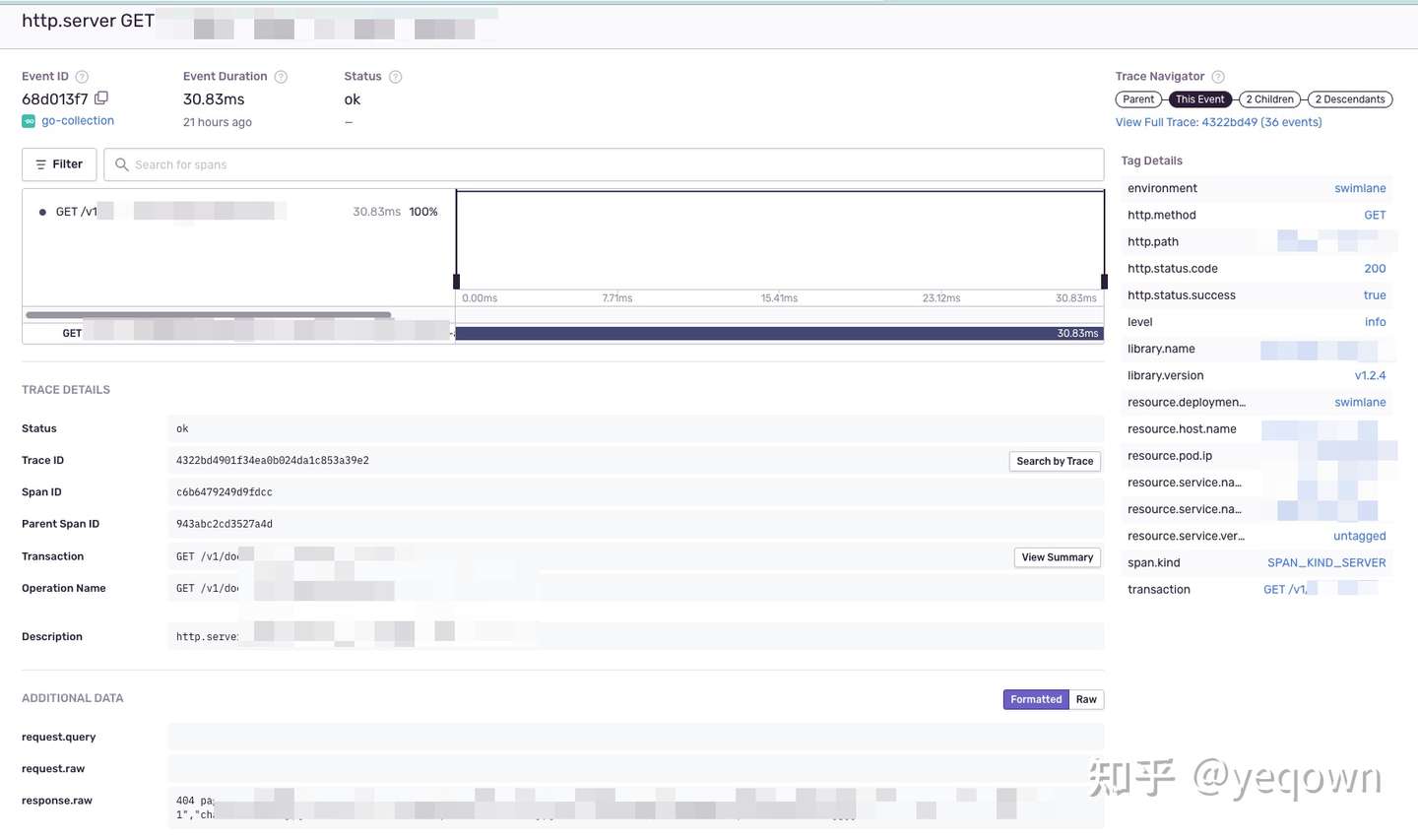
服务端链路细节,包含了服务端链路采集的标签和日志(事件)等信息。
propagation兼容jaeger效果,保证jaeger侧链路完整,使用一致的 traceId检索。因为服务侧 sentry 是渐进更新的,因此没有接入的应用并不会展示在sentry侧, 等到完全更新后就会完整。
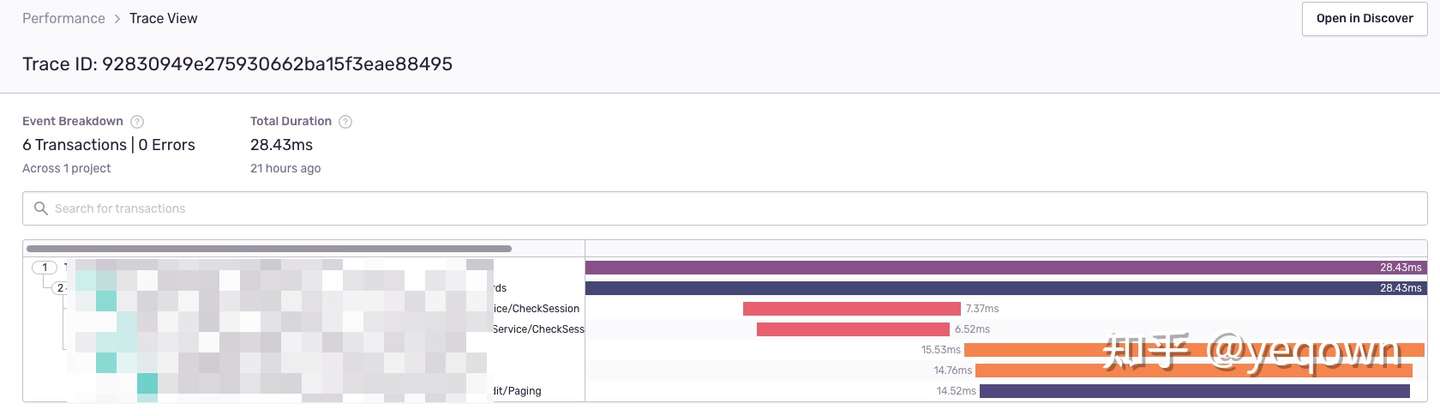
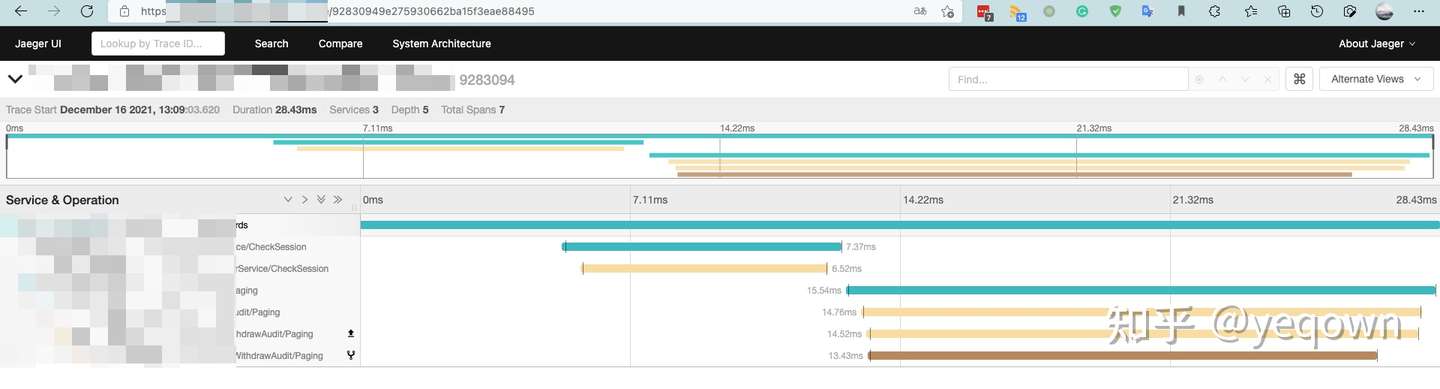
背景
#
目前运行中的链路追踪组件是采用 opentracing + jaeger 实现,这套方案唯二的不足就是:
前端采用 sentry 来采集前端页面数据(APP + WEB 都支持很好),因此才有了这么一个 前后端链路打通的需求。
...
September 27, 2020
什么是WS协议
#
The WebSocket Protocol enables two-way communication between a client
running untrusted code in a controlled environment to a remote host
that has opted-in to communications from that code. The security
model used for this is the origin-based security model commonly used
by web browsers. The protocol consists of an opening handshake
followed by basic message framing, layered over TCP.
The goal of this technology is to provide a mechanism for browser-based
applications that need two-way communication with servers that does
not rely on opening multiple HTTP connections (e.g., using XMLHttpRequest or <iframe>s and long.polling). - 摘自 RFC6455 Abstract.
...
August 6, 2020
背景
#
在没有链路追踪系统的情况下,如果只要少数几个服务,或许还可以通过日志来排查定位问题。但是如果服务一旦超过10个,那么再想通过日志来定位分析问题将无比繁琐。
因为,你先要从大量的日志中删筛选出某次请求的日志数据,才能进行后续的定位分析。
倘若日志系统也不够完善,日志对于调试毫无帮助,那又得退回到最原始的方式,通过代码断点和增加日志,等待问题复现,或者通过肉眼检查代码。
不是说这种方式不行,而是大部分的程序员的业务需求比较紧张,这样的排查手段效率和收益远远达不到要求(如果你有时间,当我没说 🐶)。
在实际场景中,我也遇到了这样的问题:
- 日志系统里包含了过少的信息,对于调试几乎没有帮助 (几乎只有错误日志,缺少输出上下文的日志)。
- 服务调用复杂,一个请求失败,只能透过错误码和错误信息进行判断是否存在调用失败的情况。
- 调用链路复杂的情况下,想要对某个请求进行优化,无从下手。
这里只列举了跟trace相关的一些原始场景,当然从上面的描述中还能发现日志系统不够完善,对调试不友好,不过这里首要解决的问题是链路追踪问题。
如果对路链路追踪没有概念,还望自行查阅资料,这里不会过多介绍~
Opentracing
#
注意:Opentracing 是一套标准接口,而不是具体实现。
这里就实战opentracing + jaeger 的链路追踪方案。其中 opentracing 是一套标准接口,而jaeger是包含了 opentracing 的实现的一套工具。
Trace链路简单示例如下:

Trace
#
描述在分布式系统中的一次"事务"。
Span
#
表示工作流的一部分的命名和定时操作。可以接受标签(Tag Key:Value),以及附加到特定span实例的标注(Annotation),如时间戳和结构化日志。
SpanContext
#
追踪伴随分布式事务的信息,包括它通过网络或通过消息总线将服务传递给服务的时间。span上下文包含TraceId、SpanId和追踪系统需要传播到下游服务的其他数据。
实战
#
这里我准备的是 Go 项目,服务之间通过gRPC通信。链路如下:
+-- process internal trace2
|
+---> process internal trace1
|
| +---> server-b trace(gRPC)
entry(HTTP) ---> server-a trace--gRPC--|
+---> server-c trace(gRPC)
|
+----> process internal trace3
从上图中可以明确,我们的目标是:实践跨服务调用和服务内部调用的链路追踪,配合jaeger我们还可以将链路信息可视化。
...