 October 10, 2023
October 10, 2023
本文如果没有特殊说明,所有的内容都是指 linux 系统
起因是从 kratos 群里看到有人问:“测了下kratos的config watch,好像对软链不生效”,他提供的屏幕截图如下类似:
$ pwd
/tmp/testconfig
$ ls -l
drwxr-xr-x 3 root root 4096 Oct 10 19:48 .
drwxr-xr-x 10 root root 4096 Oct 10 19:48 ..
drwxr-xr-x 1 root root 11 Oct 10 19:48 ..ver1
drwxr-xr-x 1 root root 11 Oct 10 19:48 ..ver2
lrwxr-xr-x 1 root root 11 Oct 10 19:48 ..data -> ..ver1
drwxr-xr-x 1 root root 11 Oct 10 19:48 data
$
$ ll -a data
drwxr-xr-x 3 root root 4096 Oct 10 19:48 .
drwxr-xr-x 10 root root 4096 Oct 10 19:48 ..
lrwxrwxrwx 1 root root 11 Oct 10 19:48 registry.yaml -> /tmp/testconfig/..data/registry.yaml
然后触发更新的动作其实是把 ..data 的源改成了 ..ver2,但是发现并没有触发更新,于是就问了一下。
...
August 22, 2023
相信了解 redis 和 openresty 的小伙伴们都知道 lua 代码可以嵌入这两种程序中运行,极大的提高了软件的扩展性;尤其是 openresty 中,通过使用 lua 我们可以很快速(相比c)的定制web服务器,或者增强 nginx 的功能。那么 lua 是如何嵌入到这些程序中的呢?lua 和 c 是如何互操作的呢?
下文的相关环境和工具版本为:Lua 5.4.6; Mac OS 13.4.1 (Darwin Kernel Version 22.5.0) arm64 M2 pro; Apple clang version 14.0.3 (clang-1403.0.22.14.1)
redis 中的 lua
#
下面展示了一段 redis 中操作 lua API 的代码:
这里出现了很多 lua_ 开头的函数,这些函数都是 lua 库中的函数,redis 通过这些函数来操作 lua 环境,
这里先不展开讲,后面会详细介绍。
更多的代码,如 luaRegisterRedisAPI 就不展示了,有兴趣的可以去看源码。
// redis-v7.2/src/eval.c#183
/* 初始化 lua 环境
*
* redis 首次启动时调用,此时 setup 为 1,
* 这个函数也会在 redis 的其他生命周期中被调用,此时 setup 为 0,但是被简化为 scriptingReset 调用。
*/
void scriptingInit(int setup) {
lua_State *lua = lua_open();
if (setup) {
// 首次启动时,初始化 lua 环境 和 ldb (Lua debugger) 的一些数据结构
lctx.lua_client = NULL;
server.script_disable_deny_script = 0;
ldbInit();
}
/* 初始化 lua 脚本字典,用于存储 sha1 -> lua 脚本的映射
* 用户使用 EVALSHA 命令时,从这个字典中查找对应的 lua 脚本。
*/
lctx.lua_scripts = dictCreate(&shaScriptObjectDictType);
lctx.lua_scripts_mem = 0;
/* 注册 redis 的一些 api 到 lua 环境中 */
luaRegisterRedisAPI(lua);
/* 注册调试命令 */
lua_getglobal(lua,"redis");
/* redis.breakpoint */
lua_pushstring(lua,"breakpoint");
lua_pushcfunction(lua,luaRedisBreakpointCommand);
lua_settable(lua, -3);
/* redis.debug */
lua_pushstring(lua,"debug");
lua_pushcfunction(lua,luaRedisDebugCommand);
lua_settable(lua,-3);
/* redis.replicate_commands */
lua_pushstring(lua, "replicate_commands");
lua_pushcfunction(lua, luaRedisReplicateCommandsCommand);
lua_settable(lua, -3);
lua_setglobal(lua,"redis");
/* 注册一个错误处理函数,用于在 lua 脚本执行出错时,打印出错信息。
* 需要注意的是,当错误发生在 C 函数中时,我们需要打印出错的 lua 脚本的信息,
* 这样才能帮助用户调试 lua 脚本。
*/
{
char *errh_func = "local dbg = debug\n"
"debug = nil\n"
"function __redis__err__handler(err)\n"
" local i = dbg.getinfo(2,'nSl')\n"
" if i and i.what == 'C' then\n"
" i = dbg.getinfo(3,'nSl')\n"
" end\n"
" if type(err) ~= 'table' then\n"
" err = {err='ERR ' .. tostring(err)}"
" end"
" if i then\n"
" err['source'] = i.source\n"
" err['line'] = i.currentline\n"
" end"
" return err\n"
"end\n";
luaL_loadbuffer(lua,errh_func,strlen(errh_func),"@err_handler_def");
lua_pcall(lua,0,0,0);
}
/* 创建一个 lua client (没有网络连接),用于在 lua 环境中执行 redis 命令。
* 这个客户端没必要在 scriptingReset() 调用时重新创建。
*/
if (lctx.lua_client == NULL) {
lctx.lua_client = createClient(NULL);
lctx.lua_client->flags |= CLIENT_SCRIPT;
/* We do not want to allow blocking commands inside Lua */
lctx.lua_client->flags |= CLIENT_DENY_BLOCKING;
}
/* Lock the global table from any changes */
lua_pushvalue(lua, LUA_GLOBALSINDEX);
luaSetErrorMetatable(lua);
/* Recursively lock all tables that can be reached from the global table */
luaSetTableProtectionRecursively(lua);
lua_pop(lua, 1);
lctx.lua = lua;
}
通过这部分代码,应该对于 lua 的嵌入式使用有了一个大概的印象。这里可以回答以下的问题:
...
August 17, 2023
假设我们有一个长连接服务,我们想要对它进行升级,但是不想让客户端受到影响应该怎么做?这个问题其实是一个很常见的问题,比如我们的游戏服务器,我们的 IM 服务器,推送服务器等等,诸如此类使用tcp长连接的服务,都会遇到这个问题。那么我们应该怎么做呢?
需求分析
#
我们可以先来看下这个场景下的需求:
- 客户端必须要对这个操作没有感知,也就是说客户端不需要做任何的修改,在服务器升级的过程中不需要配合。
- 服务器在升级的过程中,不能丢失任何的连接,也就是说,如果有新的连接进来,那么这个连接必须要被接受,如果有旧的连接,那么客户端不能够触发重连。
基本思路
#
实现思路的讨论范围限制在 linux 服务器上
为了实现上述的要求,首先在升级流程中我们需要做到以下几点:
- 旧的服务器进程在处理完请求前不能退出,而且一旦升级开始就不能再接受新的连接。
- 旧的服务器进程在所有连接都处理完毕后才能退出。
- 新的服务器进程在启动时需要继承旧的服务器进程的所有连接,新的连接也应该被新的服务器进程接受。
- 新的服务器进程也必须监听旧的服务器进程的监听端口,否则新的连接无法被接受。
那么通过 Google 和 ChatGPT 的帮助,我们可以找到一些思路:
新进程继承旧进程的(监听)套接字,而不是创建新的。
为什么不创建新的(监听)套接字呢?在 linux 中内核会把处在不同握手阶段的TCP连接放在不同的队列中(半连接/全连接)。服务器的监听套接字会有自己的队列,如果创建新的套接字,那么旧的套接字队列中的连接就会丢失。为了做到客户端无感知,我们需要继承旧的套接字(主要是为了连接队列中的连接不丢失)。
半连接队列:当客户端发送 SYN 包时,服务器会把这个连接放在半连接队列中,等待服务器的 ACK 包,这个时候连接处于半连接状态。当服务器发送 ACK 包时,这个连接就会从半连接队列中移除,放到全连接队列中,这个时候连接处于全连接状态。当服务器调用 accept 时,就会从全连接队列中取出一个连接,这个时候连接处于 ESTABLISHED 状态。
实现方式
#
那么在 linux 中,我们可以通过以如下方式实现:
- 通过
fork 创建子进程,子进程继承父进程的所有资源,包括监听套接字;
- 子进程通过
exec 加载最新的二进制程序执行,这样就实现了新进程继承旧进程的监听套接字。
- 新进程启动完成后,通知父进程退出。
- 父进程受到信号后,停止接受新的连接,等待所有的连接处理完毕后退出。
在 Go 里面,我们可以通过如下方式实现:
type gracefulTcpServer struct {
listener *net.TCPListener
shutdownChan chan struct{}
conns map[net.Conn]struct{}
servingConnCount atomic.Int32
serveRunning atomic.Bool
}
// 普通启动方式
func start(port int) (*gracefulTcpServer, error) {
ln, err := net.Listen("tcp", fmt.Sprintf(":%d", port))
// handle error ignored
s := &gracefulTcpServer{
listener: ln.(*net.TCPListener),
shutdownChan: make(chan struct{}, 1),
conns: make(map[net.Conn]struct{}, 16),
servingConnCount: atomic.Int32{},
serveRunning: atomic.Bool{},
}
return s, nil
}
// 优雅重启启动方式
func startFromFork() (*gracefulTcpServer, error) {
// ... ignored code
// 从环境变量中获取 父进程的处理的连接数,用来恢复连接
if nfdStr := os.Getenv(__GRACE_ENV_NFDS); nfdStr == "" {
panic("not nfds env")
} else if nfd, err = strconv.Atoi(nfdStr); err != nil {
panic(err)
}
// restore conn fds, 0, 1, 2 has been used by os.Stdin, os.Stdout, os.Stderr
lfd := os.NewFile(3, filepath.Join(tmpdir, "graceful"))
ln, err := net.FileListener(lfd)
// handle error ignored
s := &gracefulTcpServer{
listener: ln.(*net.TCPListener),
shutdownChan: make(chan struct{}, 1),
conns: make(map[net.Conn]struct{}, 16),
servingConnCount: atomic.Int32{},
serveRunning: atomic.Bool{},
}
// 从父进程继承的套接字中恢复连接
for i := 0; i < nfd; i++ {
fd := os.NewFile(uintptr(4+i), filepath.Join(tmpdir, strconv.Itoa(4+i)))
conn, err := net.FileConn(fd)
// handle error ignored
go s.handleConn(conn)
}
return s, nil
}
func (s *gracefulTcpServer) gracefulRestart() {
_ = s.listener.SetDeadline(time.Now())
lfd, err := s.listener.File()
// 给子进程设置 优雅重启 相关的环境变量
os.Setenv(__GRACE_ENV_FLAG, "true")
os.Setenv(__GRACE_ENV_NFDS, strconv.Itoa(len(s.conns)))
// 将父进程的监听套接字传递给子进程
files := make([]uintptr, 4, 3+1+len(s.conns))
copy(files[:4], []uintptr{
os.Stdin.Fd(),
os.Stdout.Fd(),
os.Stderr.Fd(),
lfd.Fd(),
})
// 将父进程的套接字传递给子进程
for conn := range s.conns {
connFd, _ := conn.(*net.TCPConn).File()
files = append(files, connFd.Fd())
}
procAttr := &syscall.ProcAttr{
Env: os.Environ(),
Files: files,
Sys: nil,
}
// 执行 fork + exec 调用
childPid, err := syscall.ForkExec(os.Args[0], os.Args, procAttr)
}
func main() {
// ...
// 根据环境变量判断是 fork 还是新启动
if v := os.Getenv(__GRACE_ENV_FLAG); v != "" {
s, err = startFromFork()
} else {
s, err = start(*port)
}
go s.serve()
// 处理信号,如果是 SIGHUP 信号,则执行 gracefulRestart 方法后再退出
s.waitForSignals()
}
完整代码可以在 https://github.com/yeqown/playground/golang/tcp-graceful-restart 中找到。
...
August 15, 2023
Cloudflare 自不用多说,Tunnel 是 Cloudflare 提供的一项功能,可以将本地的服务通过 Cloudflare 的网络暴露到公网,这样就可以实现内网穿透,同时还可以通过 Cloudflare 的网络加速服务,提高访问速度。
初识 Cloudflare Tunnel
#
最开始接触 Cloudflare Tunnel 是在 Twitter 上看到一个项目cloudflare-tunnel-ingress-controller ,这个项目是一个 Kubernetes 的 Ingress Controller,可以将 Kubernetes 中的服务通过 Cloudflare Tunnel 暴露到公网,这样就可以实现内网穿透,也就是说局域网搭建的服务可以通过 Cloudflare 的网络暴露到公网。
熟悉内网穿透的小伙伴,应该对这中东西很熟悉,也没什么好说的。
前提
#
Mac 上可以通过 brew install cloudflared 安装,安装完成后,可以通过 cloudflared -v 查看版本。
$ cloudflared -v
cloudflared version 2023.7.3 (built 2023-07-25T20:51:49Z)
参考 cloudflared 官方文档 安装。
使用
#
我的使用场景除了最开始提到的 Kubernetes Ingress Controller 之外,还有一个就是将局域网内的开发机通过 Cloudflare Tunnel 暴露到公网,方便远程开发。
...
January 25, 2022
背景
#
gRPC 作为服务端的常用框架,它通过 protocol-buffers 语言来定义服务,同时也约定了请求和响应的格式,这样在服务端和客户端之间就可以通过 protoc 生成的代码直接运行而不用考虑编码传输问题了。
但是,可能会遇到这样的场景:
-
RPC 响应中 无用的字段过多 , 浪费带宽和无效计算,如下图所示:
这里的无用字段是指,在响应中,没有用到的字段,这些字段可以忽略掉,不会影响客户端的使用。
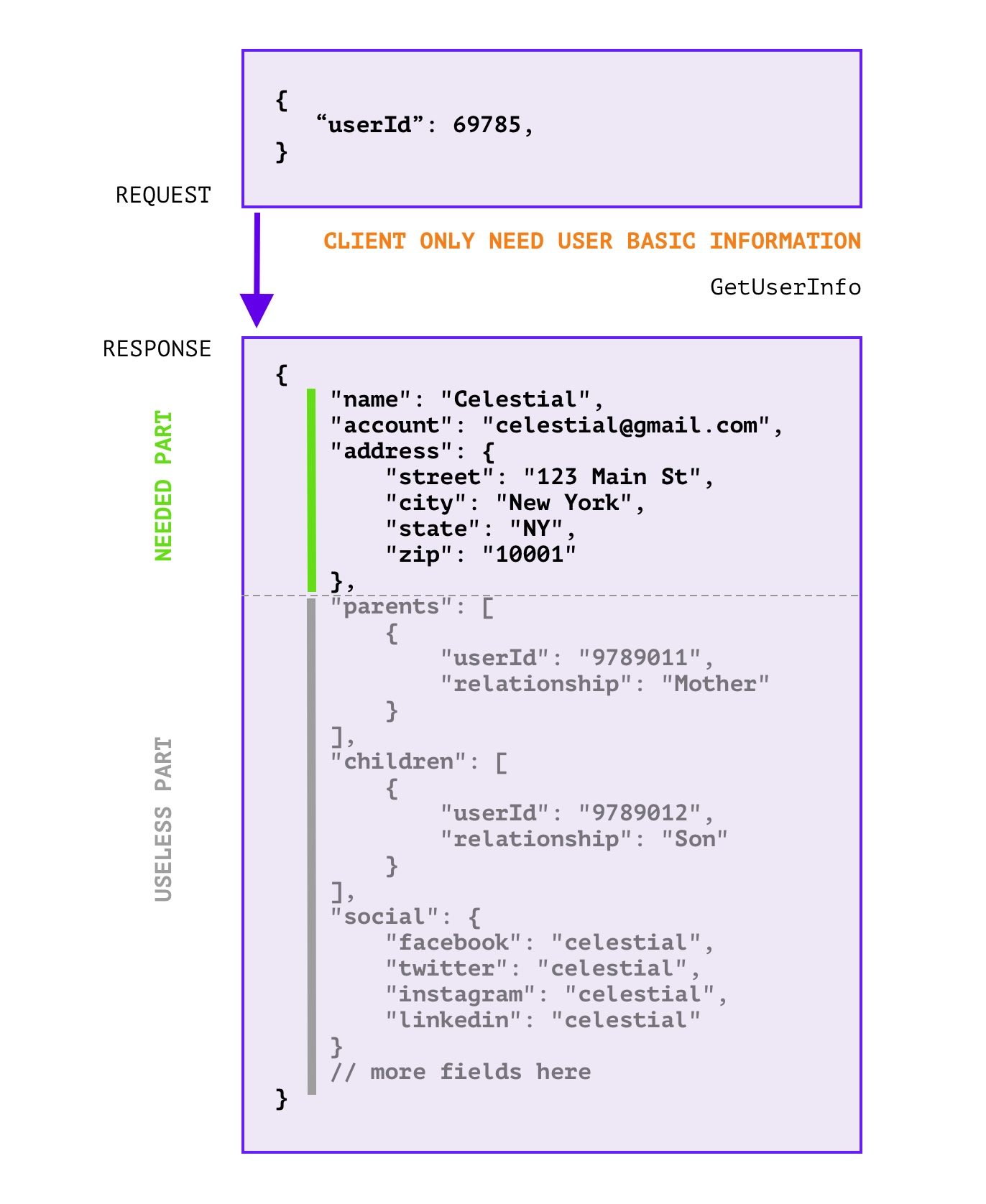
或许 拆分接口 是一个好的办法,但是可能会因为这样那样的原因(信息粒度降低导致接口太多了,有些地方就是需要聚合信息;细粒度的API设计同时会导致代码重复增加),可能无法推动拆分改造。同时如果没有拆分标准,亦或团队内成员不能严格遵守标准,那么拆分也只是重复问题而已。
-
RPC 增量更新时,如何判断零值字段是否需要更新?
对于 unset 和 zero value 不好区分的语言中(比如:go),在提供服务的一方遇到 增量更新 的场景时就会遇到这样的情况:
对于这种情况当然可以也有一些方法来解决,比如:使用指针来定义数据基本类型,那么在使用的时候如果判定为 nil 就说明没有设置,如果不为 nil 且为零值,那么就说明也是需要更新的。不过这样解决的缺点就是,nil refference panic 的概率又增加了,在使用时也稍微麻烦了一点。
 ·
·
解决方案
#
其实我们在思考上述两种场景的时候,把 客户端 和 服务端 的角色提取出来,就会发现这两个场景都是从 服务端 的视角遇到的问题,两个场景都是类似的:
- 客户端需要哪些字段,服务端不知道
- 客户端更新了哪些字段,服务端也不知道
但是,其实客户端是知道的,因此让客户端把这部分信息传递给服务端就行了。因此我们可以用 FieldMask 字段,用来传递客户端需要的字段,服务端就只返回需要的字段;客户端的告诉服务端需要哪些字段,服务端就更新哪些字段。
但是 FieldMask 只是一个定义,在具体的使用场景中还需要开发者自己编写一些辅助方法,来实现功能。那么是不是可以提供一个插件,让开发者可以只编写 proto 文件,便可以自动生成一些辅助方法呢?答案是肯定的,预览效果如下:
message UserInfoRequest {
string user_id = 1;
google.protobuf.FieldMask field_mask = 2 [
(fieldmask.option.Option).in = {gen: true},
(fieldmask.option.Option).out = {gen: true, message:"UserInfoResponse"}
];
}
message Address {
string country = 1;
string province = 2;
}
message UserInfoResponse {
string user_id = 1;
string name = 2;
string email = 3;·
Address address = 4;
}
message NonEmpty {}
service UserInfo {
rpc GetUserInfo(UserInfoRequest) returns (UserInfoResponse) {}
rpc UpdateUserInfo(UserInfoRequest) returns (NonEmpty) {}
}
生成的代码如下:
...
December 15, 2021
自从微服务大行其道,容器化和k8s编排一统天下之后,“可观测性” 便被提出来。这个概念是指,对于应用或者容器的运行状况的掌控程度,其中分为了三个模块:Metrics、Tracing、Logging。Metrics 指应用采集的指标;Tracing 指应用的追踪;Logging 指应用的日志。
日志自不用多说,这是最原始的调试和数据采集能力。Metrics 比较火的方案就是 Prometheus + Grafana,思路就是通过应用内埋入SDK,选择 Pull 或者 Push 的方式将数据收集到 prometheus 中,然后通过 Grafana 实现可视化,当然这不是本文的重点就此略过。
Tracing 也并不是可观测性提出后才诞生的概念,在微服务化的进程中就已经有Google的Dapper落地实践,并慢慢形成 OpenTracing 规范,这一规范又被多家第三方框架所支持,如 Jaeger、Zipkin 等。OpenTelemetry 就是结合了 OpenTracing + OpenCensus 规范,约定并提供完成的可观测性套件,只是目前(2021-12-15)稳定下来的只有 Tracing 这一部分而已。对 OpenTelemetry 发展历史感兴趣的可以自行了解。
效果预览
#
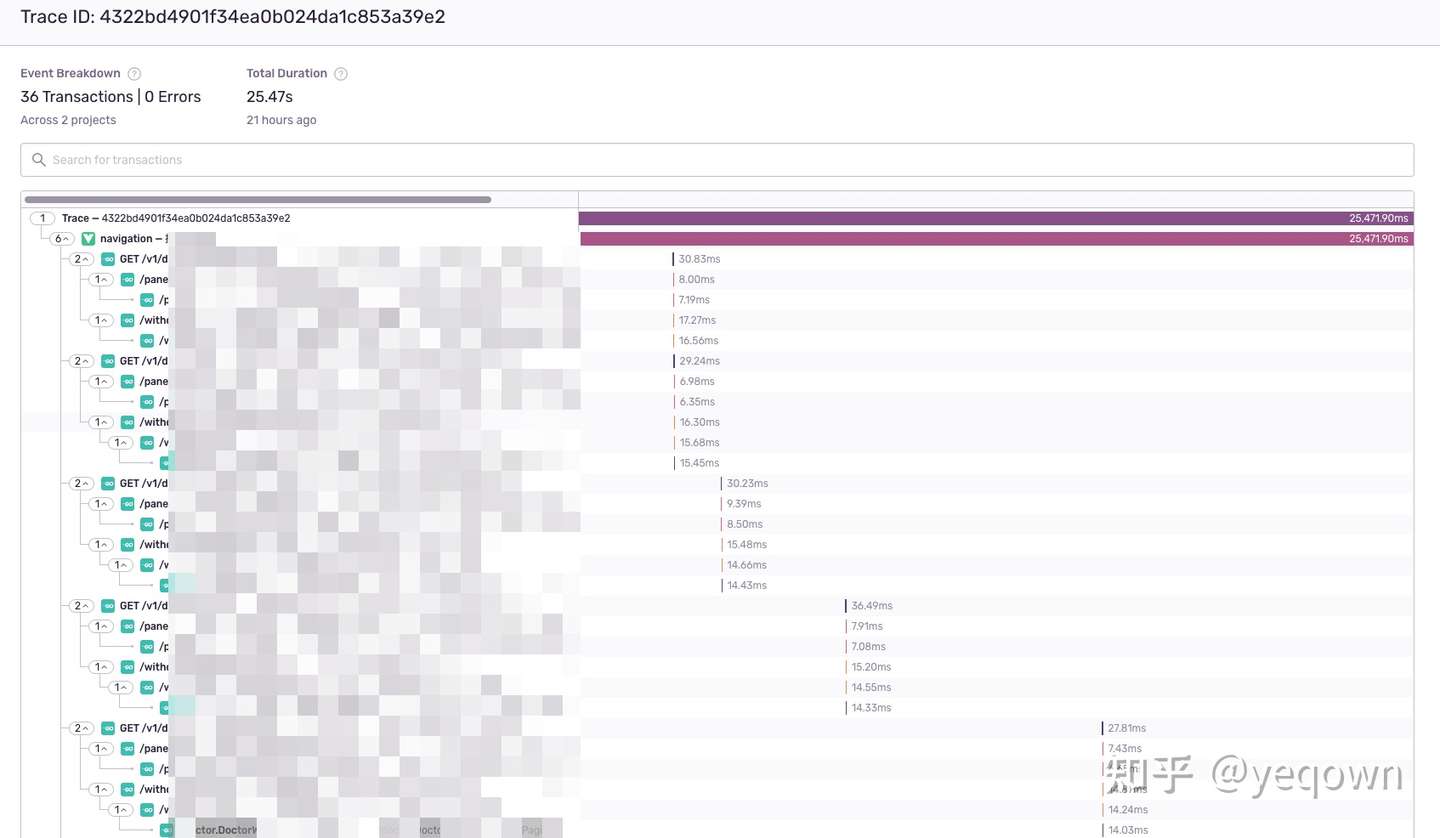
链路总览,包含了前端页面的生命周期 + 整个了链路采集到的Span聚合。
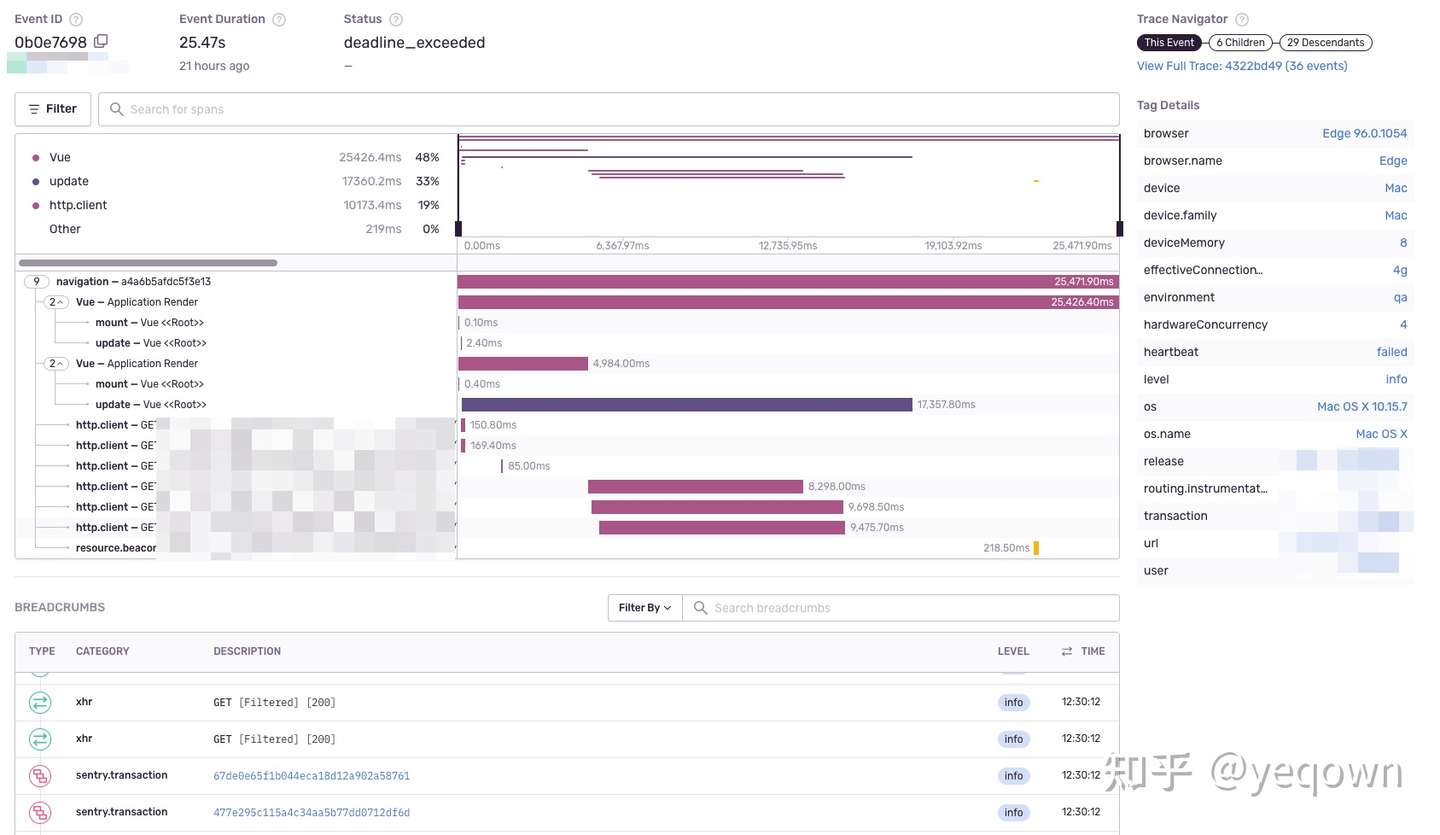
前端页面指标采集概览,包含了该页面生命周期内的动作和日志等。
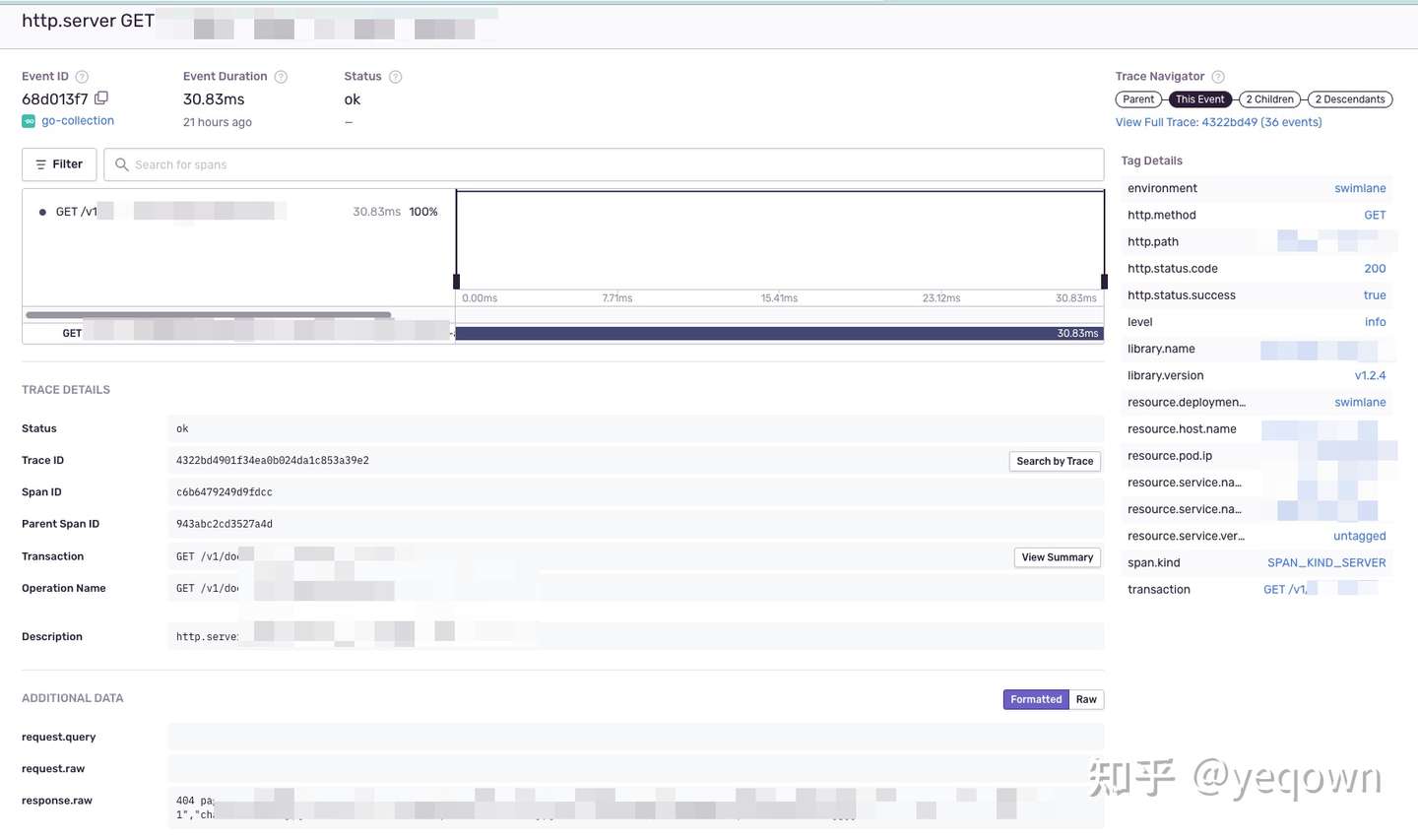
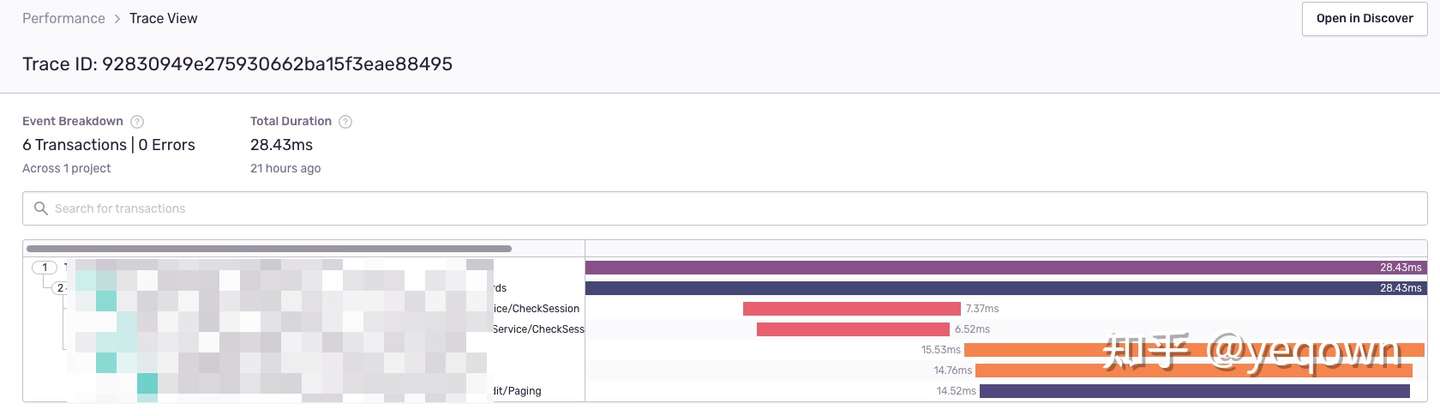
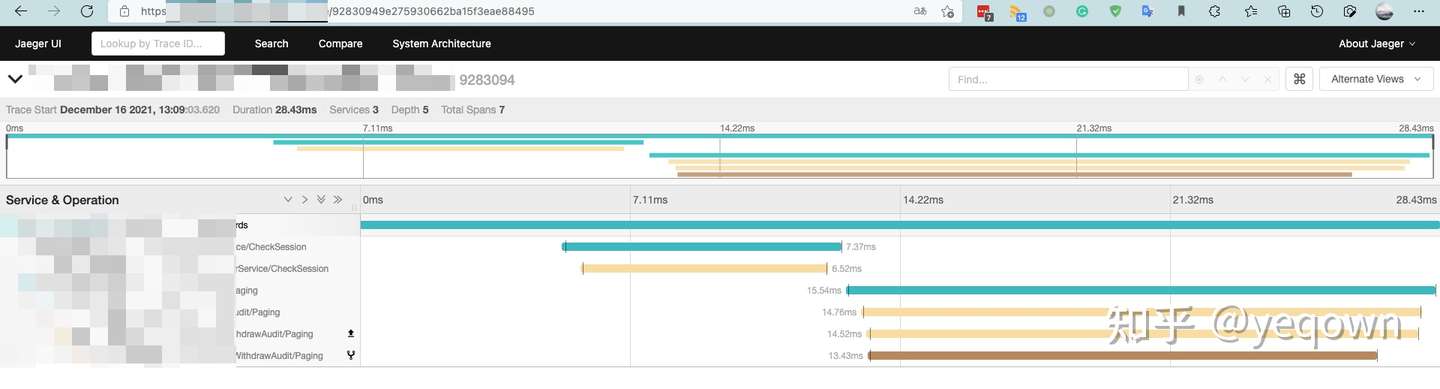
服务端链路细节,包含了服务端链路采集的标签和日志(事件)等信息。
propagation兼容jaeger效果,保证jaeger侧链路完整,使用一致的 traceId检索。因为服务侧 sentry 是渐进更新的,因此没有接入的应用并不会展示在sentry侧, 等到完全更新后就会完整。
背景
#
目前运行中的链路追踪组件是采用 opentracing + jaeger 实现,这套方案唯二的不足就是:
前端采用 sentry 来采集前端页面数据(APP + WEB 都支持很好),因此才有了这么一个 前后端链路打通的需求。
...
September 22, 2020
背景
#
第一次,线上遇到大量接口RT超过10s触发了系统告警,运维反馈k8s集群无异常,负载无明显上升。将报警接口相关的服务重启一番后发现并无改善。但是开发人员使用链路追踪系统发现,比较慢的请求总是某个gRPC服务中的几个POD导致,由其他POD处理的请求并不会出现超时告警。
第二次,同样遇到接口RT超过阈值触发告警,从k8s中查到某个gRPC服务(关键服务)重启次数异常,查看重启原因时发现是OOM Killed,OOM killed并不是负载不均衡直接导致的,但是也有一定的关系,这个后面再说。前两次由于监控不够完善(于我而言,运维的很多面板都没有权限,没办法排查)。期间利用pprof分析了该服务内存泄漏点,并修复上线观察。经过第二次问题并解决之后,线上超时告警恢复正常水平,但是该 deployment 下的几个POD占用资源(Mem / CPU / Network-IO),差距甚大。


第二张图是运维第一次发现该服务OOM killed 之后调整了内存上限从 512MB => 1G,然而只是让它死得慢一点而已。
从上面两张图能够石锤的是该服务一定存在内存泄漏。Go项目内存占用的分析,我总结了如下的排查步骤:
1. 代码泄漏(pprof)(可能原因 goroutine泄漏;闭包)
2. Go Runtime + Linux 内核(RSS虚高导致OOM)https://github.com/golang/go/issues/23687
3. 采集指标不正常(container_memory_working_set_bytes)
2,3 是基于第1点能基本排除代码问题的后续步骤。
解决和排查手段:
1. pprof 通过heap + goroutine 是否异常,来定位泄漏点
运行`go tool pprof`命令时加上--nodefration=0.05参数,表示如果调用的子函数使用的CPU、memory不超过 5%,就忽略它。
2. 确认go版本和内核版本,确认是否开启了MADV_FREE,导致RSS下降不及时(1.12+ 和 linux内核版本大于 4.5)。
3. RSS + Cache 内存检查
> Cache 过大的原因 https://www.cnblogs.com/zh94/p/11922714.html
// IO密集:手动释放或者定期重启
查看服务器内存使用情况: `free -g`
查看进程内存情况: `pidstat -rI -p 13744`
查看进程打开的文件: `lsof -p 13744`
查看容器内的PID: `docker inspect --format "{{ .State.Pid}}" 6e7efbb80a9d`
查看进程树,找到目标: `pstree -p 13744`
参考:https://eddycjy.com/posts/why-container-memory-exceed/
通过上述步骤,我发现了该POD被OOM killed还有另一个元凶就是,日志文件占用。这里就不过多的详述了,搜索方向是 “一个运行中程序在内存中如何组织 + Cache内存是由哪些部分构成的”。这部分要达到的目标是:一个程序运行起来它为什么占用了这么些内存,而不是更多或者更少。
...
August 12, 2020
背景
#
在 github.com/yeqown/goreportcard 项目中我改造了 goreportcard。
后续为了方便部署,我准备将其打包成为docker镜像并上传到 DockerHub。期间遇到了下面的问题,并一一解决,这里做一个记录帮助以后遇到类似的问题可以快速解决。
初期的目标是:将goreportcard和golangci-lint编译好,尽可能较小镜像的体积。因此第一次尝试,我使用了分阶段编译,用golang:1.14.1编译,alpine来发布。
基本 Dockerfile 如下:
# building stage
FROM golang:1.14-alpine3.11 as build
WORKDIR /tmp/build
COPY . .
RUN export GOPROXY="https://goproxy.cn,direct" \
&& go mod download \
&& go build -o app ./cmd/goreportcard-cli/ \
&& go get github.com/golangci/golangci-lint && go install github.com/golangci/golangci-lint/cmd/golangci-lint
# release stage
FROM golang:1.14-alpine3.11 as release
WORKDIR /app/goreportcard
COPY --from=build /tmp/build/app .
COPY --from=build /tmp/build/tpl ./tpl
COPY --from=build /tmp/build/assets ./assets
# FIXED: 不能使用golangci-lint, `File not found` 错误
COPY --from=build /go/bin/golangci-lint /usr/local/bin
EXPOSE 8000
ENTRYPOINT ["./app", "start-web", "&"]
问题清单和解决方案
#
由于并不是所有的问题都和Docker有关,因此我会使用 [分类] 在标题上注明。
...
March 29, 2020
redis主从复制是高可用方案中的一部分,那主从复制是如何进行的?又是如何实现的?怎么支撑了redis的高可用性?在主从模式下Master和Slave节点分别做了哪些事情?
redis高可用方案是什么?
#
我理解的redis高可用的特点有:
- 高QPS,主从 => 读写分离
- 高容量,集群分片 => 高容量
- 故障转移,sentinel => 故障转移
- 故障恢复,数据持久 => 故障恢复 ~ 这里我简单的理解(RDB + AOF)= 故障恢复
主从复制
#
redis 主从复制有两个版本:旧版(Ver2.8-),新版(Ver2.8+,增加PSYNC命令来解决旧版中的问题)
讨论复制时都需要考虑两种场景:
- 场景1:从节点刚刚上线,需要去同步主节点时,这部分可以理解为 全量复制。
- 场景2:从节点掉线,恢复上线后需要同步数据,使自己和主节点达到一致状态。这部分在旧版复制里等价于全量复制,在新版里可以理解为增量复制。
当然你肯定会想到如果主节点掉线,这时候会怎么样?这个场景当然也在redis高可用方案中,之时不是本文的重点,属于Sentinel机制的内容了。
旧版主从复制
#
前文说过了,旧版主从复制只有全量复制用于应付上述两个场景,因此下面的流程也只有一份:
- 从服务器向主服务器发送sync命令。
- 主服务器在收到sync命令之后,调用bgsave命令生成最新的rdb文件,将这个文件同步给从服务器,这样从服务器载入这个rdb文件之后,状态就会和主服务器执行bgsave命令时候的一致。
- 主服务器将保存在命令缓冲区中的写命令同步给从服务器,从服务器执行这些命令,这样从服务器的状态就跟主服务器当前状态一致了。
如果你不知道redis中还有个缓冲区的话,建议系统的了解下redis中缓冲区的设计。这里缓冲区特指命令缓冲区,后面还会讲到复制缓冲区。

但是这样的实现在 场景2 下的缺点很明显:如果说从节点断线后迅速上线,这段时间内的产生的写命令很少,却要全量复制主库的数据,传输了大量重复数据。
SYNC命令产生的消耗:
1. 主节点生成RDB,需要消耗大量的CPU,内存和磁盘IO
2. 网络传输大量字节数据,需要消耗主从服务器的网络资源
3. 从节点需要从RDB文件恢复,会造成阻塞无法接受客户端请求
优点就是:简单暴力。个人看来在redis架构中不合适的用法,不代表说实际场景中也一定不合适,简单暴力也是一个很大的优点。
新版主从复制
#
新版的主从复制跟旧版的区别就在于:对场景2的优化。
场景2的缺点上文已经提到过了,那么优化的方向就是**“尽量不使用全量复制;增加增量复制(PSYNC)的功能”**。为此还要解决下列问题:
- 如果某个从节点断线了,重新上线该从节点如何知道自己是否应该全量还是增量复制呢?
- 该从节点断线恢复后,又怎么知道自己缺失了哪些数据呢?
- 主节点又如何补偿该从节点在断线期间丢失的那部分数据呢?旧版的复制除了RDB,还有从命令缓冲区中的写命令来保持数据一致。
为此新版中使用了以下概念:
运行ID - runid
#
每个redis服务器都有其runid,runid由服务器在启动时自动生成,主服务器会将自己的runid发送给从服务器,而从服务器会将主服务器的runid保存起来。从服务器redis断线重连之后进行同步时,就是根据runid来判断同步的进度:
- 如果前后两次主服务器runid一致,则认为这一次断线重连还是之前复制的主服务器,主服务器可以继续尝试部分同步操作。
- 如果前后两次主服务器runid不相同,则全同步流程。
复制偏移量 - offset
#
主从节点,分别会维护一个复制偏移量:
主服务器每次向从服务器同步了N字节数据之后,将修改自己的复制偏移量+N。从服务器每次从主服务器同步了N字节数据之后,将修改自己的复制偏移量+N。通过对比主从节点的偏移量很容易就可以发现,主从节点是否处于一致状态。
...
January 8, 2020
背景
#
生产环境数据库不允许直接访问,但是又经常有需要直接操作数据库的需求😂。先不说合不合理,背景就是这个背景,因此只能通过跳板机来连接数据库,一(就)般(我)来(而)说(言)会使用ssh隧道,就轻松能解决这个问题,然鹅,事情并不简单。这里陈述一下:
- 生产环境数据库不让直接访问;
- 跳板机上没有公钥,没有权限;
- 我一次可能需要开3+个隧道才能启动服务【敲重点】
解决
#
本着“我不造轮子,谁来造轮子”的想法,这里就造一个小轮子:用Go来实现SSH隧道多开,并支持配置。成果预览:


原理简要分析
#
如果代理原理有点了解,这里的原理差不多是一样的:Local <-> SSH tunnel <-> Remote Server,对于隧道来说把Local的请求传给Remote, 把Remote的响应告诉Local。直接上代码:
// Start .
// TODO: support random port by using localhost:0
func (tunnel *SSHTunnel) Start() error {
listener, err := net.Listen("tcp", tunnel.LocalAddr)
if err != nil {
return err
}
defer listener.Close()
// tunnel.Local.Port = listener.Addr().(*net.TCPAddr).Port
for {
conn, err := listener.Accept()
if err != nil {
return err
}
logger.Infof(tunnel.name() + " accepted connection")
go tunnel.forward(conn)
}
}
// 创建隧道并传递消息,分别有两个端点,一个是本地隧道口,另一个是远程服务器上的隧道口
func (tunnel *SSHTunnel) forward(localConn net.Conn) {
// 创建本地到跳板机的SSH连接
serverSSHClient, err := ssh.Dial("tcp", tunnel.ServerAddr, tunnel.SSHConfig)
if err != nil {
logger.Infof(tunnel.name()+" server dial error: %s", err)
return
}
logger.Infof(tunnel.name()+" connected to server=%s (1 of 2)", tunnel.ServerAddr)
// 创建跳板机到远程服务器的连接
remoteConn, err := serverSSHClient.Dial("tcp", tunnel.RemoteAddr)
if err != nil {
logger.Infof(tunnel.name()+" remote dial error: %s", err)
return
}
logger.Infof(tunnel.name()+" connected to remote=%s (2 of 2)", tunnel.RemoteAddr)
copyConn := func(writer, reader net.Conn) {
_, err := io.Copy(writer, reader)
if err != nil {
logger.Infof(tunnel.name()+" io.Copy error: %s", err)
}
}
// local(w) => 远程(r)
go copyConn(localConn, remoteConn)
// 远程(w) => 本地(r)
go copyConn(remoteConn, localConn)
}
代码中需要注意的是:
...