 October 16, 2025
October 16, 2025
之前的博客 Kafka Connect Mongodb 反复快照 - 大数据集快照
本文中使用的 MongodbSourceConnector 是 io.debezium.connector.mongodb.MongoDbConnector 2.2.1.Final。
机制简介
#
为了提供管理快照的灵活性,Debezium 包含一个补充快照机制,称为增量快照。增量快照依赖于 Debezium 机制向 Debezium 连接器发送信号。‼️ 增量快照运行时,不会阻塞变更流事件处理。
初始快照会先保存 change stream 的位点,开始执行全量快照,全量快照完成后,再从保存的位点开始增量处理变更事件。
目前 Debezium 支持增量快照的连接器有:
- Db2
- MariaDB (Technology Preview)
- MongoDB
- MySQL
- Oracle
- PostgreSQL
- SQL Server
发送这个信号支持多种方式,通过配置 signal.enabled.channels 来指定,默认为 source(也就是数据集合方式),可选值有:source、kafka、file 和 jmx:
- source 源数据库: 配置
signal.data.collection 来指定集合
- kafka: 配置
signal.kafka.topic 来指定 topic
- file: 配置
signal.file 来指定文件路径,写入文件的格式数据为 JSON,字段取值参考下面的表格。
- jmx: 启用
JMX MBean Server 来暴露 signaling bean
需要启用增量快照时,只需要向特定方式中写入数据即可。如果是 source 只需要向数据库中插入一条数据,如果是 kafka 那么则是投递一条消息。
...
October 14, 2025
使用的 Apache Doris 版本:3.0.3, 对应的 Doris 源码如果没有特意说明,均为 3.0.3 版本。
背景
#
运营反馈了一些业务异常,这些异常都指向了一个 Doris 数据查询服务(后都用 DQ-1 指代),该服务日志中存在大量的错误日志,如下:
platformAwardBiz.GetByID failed: Error 1047 (08S01): msg: Not supported such prepared statement
日志中发现,全部的查询均报了 Not supported such prepared statement 错误,而不是存在特定的查询语句。而与此同时,另外的 Doris 查询服务 (后使用 DQ-2 指代) 并没有出现该错误日志。
DQ-1 使用 golang 编写,使用了 gorm 作为连接 Doris 的查询工具。DQ-2 使用了 python3编写,使用了 pymysql 作为连接 Doris 的查询工具。
发现问题后,猜测是 prepared statement 机制的相关问题,快速解决方案选择了重启 DQ-1 和 Doris FE 节点,然后错误消失。
问题分析
#
首先从日志入手,采集了 FE 的错误日志,但经过排查没有发现明显的异常日志。经过检索搜索引擎和社区,也没有发现有相关的 issue。
那只能从源码入手了。在进去源码分析之前,这里带着几个疑问:
...
September 28, 2025
本文中使用的 Kafka 版本为 v3.3.2
引言
#
Kafka MirrorMaker2 是 Kafka 官方提供的跨集群数据复制工具, 它是基于 Kafka Connect 框架构建的。MirrorMaker2 支持多种部署模式, 包括 Dedicated 模式和 Connect 集群模式,还有 standalone 模式。
其中, Dedicated 模式有一个启动脚本 kafka-mirror-maker.sh, 该脚本会启动一个独立的 MirrorMaker2 实例, 而不需要依赖 Kafka Connect 集群。Dedicated 模式适合小规模的复制任务, 但在大规模部署中, 它缺乏可扩展性和高可用性。
相比之下, Connect 集群模式则是先搭建出一个 Kafka Connect 集群, 再提交 MirrorMaker2 的 MirrorSourceConnector 任务。这种模式下, 可以通过增加或减少 Connect 工作节点来动态调整复制任务的资源, 具备更好的弹性和容错能力。
当然配置上也会更复杂一些, 需要管理 Connect 集群的配置和任务。
那么, 如果我们已经在使用 Dedicated 模式部署了 MirrorMaker2, 但现在需要切换到 Connect 集群模式, 应该如何操作呢? 本文将介绍从 Dedicated 模式迁移到 Connect 集群模式时,怎么处理已经同步的 offset 进度, 以确保数据的一致性和连续性。
...
July 2, 2025
本文主要聚焦于 WebAssembly 的核心规范(Core Spec)部分。WASI 和 Embedder Spec 等其他部分并非本文的重点,感兴趣的读者可自行查阅相关资料。

目的
#
随着 Web 技术的普及,越来越多的应用场景(如游戏、音视频处理、AI 等)需要在浏览器中运行。这些场景通常涉及 CPU 密集型任务,而现有 Web 引擎在处理此类任务时,性能仍不及原生语言。此外,C/C++ 等语言已积累了大量成熟的库,为了高效复用这些库以扩展 Web 的能力,急需一种新方式,使 C++/Rust 等语言也能在浏览器环境中运行。
为解决上述问题,W3C 提出了 WebAssembly 规范。该规范设计了一种全新的、与机器无关的汇编指令集、运行时(可理解为虚拟机)以及内存模型等。
WebAssembly 规范发布后,各大浏览器厂商迅速跟进支持,使其成为一种跨平台的二进制格式,能够在不同操作系统和硬件平台上运行。WASM 的应用范围也因此不再局限于 Web 场景,而是扩展到移动端、服务器端等领域。在云原生领域,Envoy、Kong 和 Apisix 等项目已支持 WASM 作为其扩展插件。WasmEdge 更进一步,直接提出将 WASM 应用于边缘计算场景,例如无服务器应用和函数即服务等。
核心概念
#
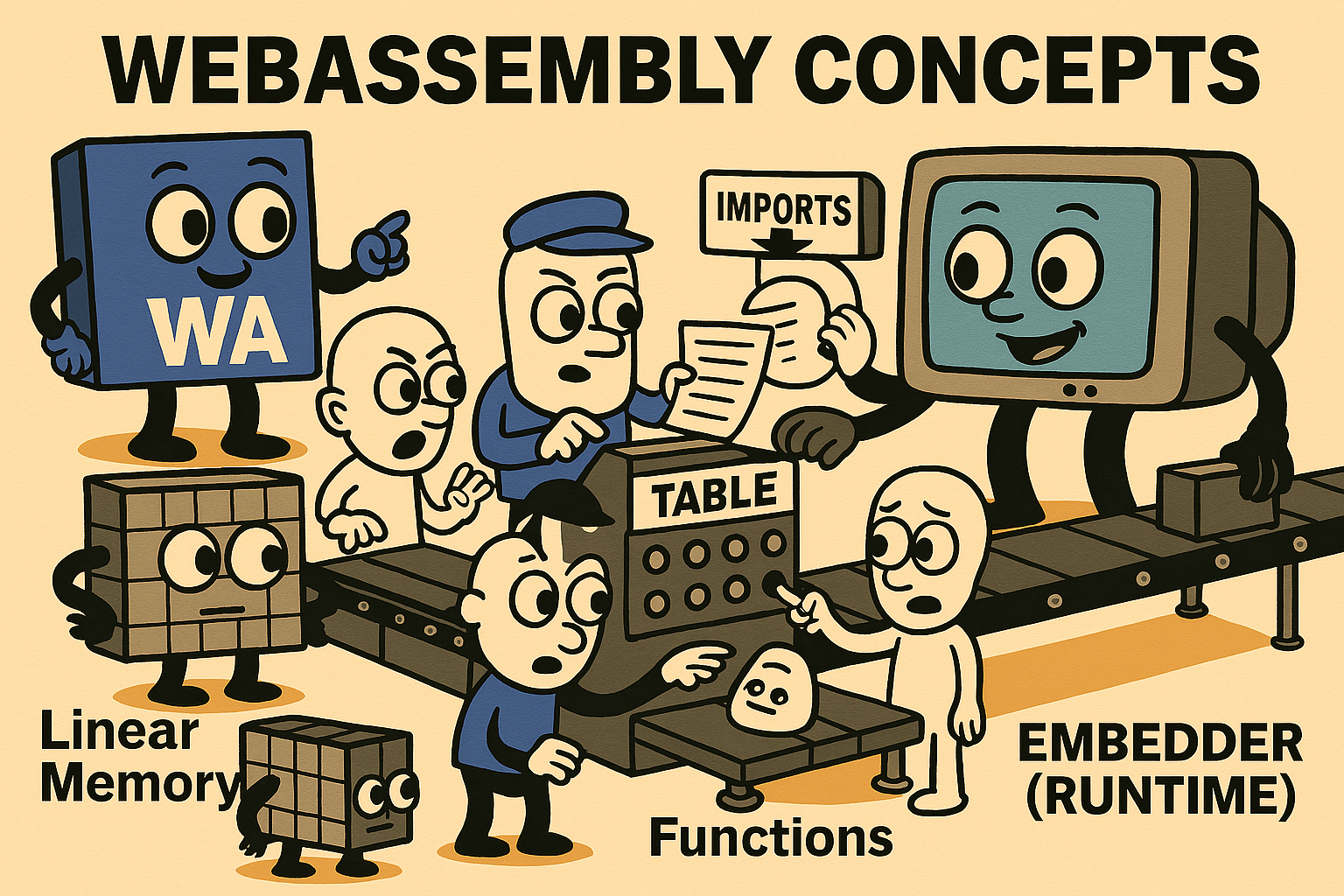
在最新规范中,WebAssembly 定义了以下核心概念:
| 概念 |
解释说明 |
| Values |
提供四种基础数值类型:32位和64位的整型及浮点型。32位整型可用于表示布尔值或内存地址。另有128位扩展整型用于高精度计算。 |
| Instructions |
基于栈式虚拟机执行的指令,分为简单指令和控制指令两类。 |
| Traps |
类似异常机制,当发生非法操作(如越界访问)时立即中止执行并报告宿主环境。功能类似于Go/Rust中的panic。 |
| Functions |
与其他编程语言一致,用于组织特定功能的代码,接收参数并返回结果。 |
| Tables |
数据结构上是一个数组,用于存储特定类型(funcref和externref),可通过索引模拟函数指针。 |
| Linear Memory |
一段可动态增长的连续字节数组,程序可存储和加载其中任意位置的数据,越界访问会触发Trap。 |
| Modules |
包含类型、函数、表、内存和全局变量的定义,作为部署、加载和编译的基本单位。可声明导入导出项,并支持定义自动执行的启动函数。 |
| Embedder |
指将WebAssembly程序嵌入宿主环境的实现方式,如wasmtime或Web环境中的WebAssembly运行时。 |
举例分析
#
接下来,我们将结合一个简单的 WASM 程序来辅助理解 WebAssembly 规范的内容。这里使用 Rust 语言编写一个简单的加法程序,并将其编译为 WASM 模块:
...
April 24, 2025
Kafka 和 MongoDB 是目前使用比较广泛的消息队列和数据库,在之前的很长时间里对这两个软件系统的理解都停留在概念和使用上,直到最近遇到一个“诡异”的问题,已有的经验和调试方法无法定位时,最终尝试了下抓包分析才最终定位到问题的根源。
问题描述:
使用 sarama 编写了一个 kafka 消费者组,这里不同寻常的地方在于:手动提交 + 批量消费。遇到的问题:某些分区消费进度无法成功提交,但是消息是消费成功的。出现这种情况的分区没有规律,触发 rebalance 后 “故障分区” 有概率会发生变化。
分析/定位:这里很明显的问题在于手动提交 offset 为什么不成功?从实现来说,提交 offset 的逻辑跟分区没有关系是一致,那这种不确定性故障时从哪儿来的?而且还和 rebalance 相关。
梳理下 kafka 客户端消费提交涉及到的操作:Fetch, OffsetCommit, 但是消费是正常的,那么只需要抓包分析 OffsetCommit 就可以知道 offset 提交存在什么问题。
结果:
通过抓包一切都明朗了:出现问题的分区同时有多个 OffsetCommit 请求,且其中有的请求提交的 offset 一致停留在一个 “旧的” 位置,不会更新,这样就缩小了范围:程序提交 offset 逻辑异常。
KAFKA 协议
#
Kafka 协议是基于 TCP/IP 协议的二进制协议。其结构组成如下:
struct RequestOrResponse {
RequestResponseHeader requestResponseHeader; // uint32 messageLength;
SpecificRequestOrResponseHeader body; // 格式取决于具体的请求和响应,比如:RequestV1Header
}
struct RequestV1Header {
int16 apiKey;
int16 apiVersion;
int32 correlationId;
string clientId;
}
协议结构
#
https://kafka.apache.org/protocol.html#protocol_messages
...
February 28, 2025
本文记录了在 ubuntu 22.04 上配合 minikube 搭建的 k8s 集群,搭建 doris 存算分离集群的过程。
0. 环境信息
#
| 软件 |
版本 |
| OS |
Ubuntu 24.04.1 LTS x86_64 |
| kernel |
6.8.0-52-generic |
| minikube |
v1.35.0 |
| kubernetes |
v1.32.0 |
| doris |
v3.0.3 |
这里默认已经准备好了基础的 kubernetes 集群,所以也不再阐述如何通过 minikube 或者其他方式搭建 kubernetes 集群。
1. 安装 FoundationDB
#
参考文档:https://doris.apache.org/zh-CN/docs/3.0/install/deploy-on-kubernetes/separating-storage-compute/install-fdb
1.1 安装 FoundationDB CRD 资源
#
kubectl apply -f https://raw.githubusercontent.com/FoundationDB/fdb-kubernetes-operator/main/config/crd/bases/apps.foundationdb.org_foundationdbclusters.yaml
kubectl apply -f https://raw.githubusercontent.com/FoundationDB/fdb-kubernetes-operator/main/config/crd/bases/apps.foundationdb.org_foundationdbbackups.yaml
kubectl apply -f https://raw.githubusercontent.com/FoundationDB/fdb-kubernetes-operator/main/config/crd/bases/apps.foundationdb.org_foundationdbrestores.yaml
1.2 部署 FoundationDB Operator
#
wget https://raw.githubusercontent.com/apache/doris-operator/master/config/operator/fdb-operator.yaml
kubectl apply -f fdb-operator.yaml
1.3 部署 FoundationDB 集群
#
wget https://raw.githubusercontent.com/foundationdb/fdb-kubernetes-operator/main/config/samples/cluster.yaml -O fdb-cluster.yaml
kubectl apply -f fdb-cluster.yaml
# 查看集群状态
kubectl get fdb
# 预期输出(启动需要时间,需要等待几分钟)
NAME GENERATION RECONCILED AVAILABLE FULLREPLICATION VERSION AGE
test-cluster 1 1 true true 7.1.26 3m30s
2. 安装 Doris Operator
#
2.1 安装 CRD 部署 Doris 相关资源定义
#
kubectl create -f https://raw.githubusercontent.com/apache/doris-operator/master/config/crd/bases/crds.yaml
2.2 部署 Doris Operator
#
wget https://raw.githubusercontent.com/apache/doris-operator/master/config/operator/disaggregated-operator.yaml -O disaggregated-operator.yaml
kubectl apply -f disaggregated-operator.yaml
# 查看部署状态
kubectl get pod -n doris
# 预期输出
NAME READY STATUS RESTARTS AGE
doris-operator-5fd65d8d69-rgqlk 1/1 Running 0 79s
3. 部署存算分离集群
#
3.1 下载示例配置
#
wget https://raw.githubusercontent.com/apache/doris-operator/master/doc/examples/disaggregated/cluster/ddc-sample.yaml -O ddc-sample.yaml
3.2 配置 ConfigMap
#
对于 ddc-sample.yaml 配置进行调整配置。这三个都需要分别配置 ConfigMap 并修改集群中的配置挂载。
...
January 3, 2025
memcached 是一个高性能的“分布式”内存对象缓存系统,用于动态 Web 应用以减轻数据库负载。它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高动态、数据库驱动网站的速度。memcached 是自由软件,以 BSD 许可证发布。
相比于大家熟知的 Redis,memcached 更加简单,只支持 key-value 存储,而 Redis 支持更多的数据结构,如 list、set、hash 等。
Github 地址:https://github.com/memcached/memcached
为什么有 redis 还要使用 memcached
#
从我个人的角度来说,要在采用一个缓存系统的时候,我会优先选择 Redis,因为 Redis 功能更加强大,支持更多的数据结构,而且 Redis 也支持持久化,在高可用和分布式部分的设计上也更加完善。
但是 memcached 也有自己的优势,比如更加简单,更加轻量级,更加容易上手,因此在某些系统中也会选用 memcached。因此,了解 memcached 的设计也是有必要的。
memcached 协议概览
#
memcached 支持基本的文本协议和元文本协议,其中元文本协议于 2019 年推出。memcached 还曾支持过二进制协议,但已经被废弃。
memcached 的协议是基于文本的,因此我们可以通过 telnet 或者 netcat 工具来模拟 memcached 的客户端,从而方便的进行测试。
这两者是 “交叉兼容” 的,也就是说我们可以通过 文本协议来设置键值, 通过 元文本协议来查询,反之亦然。
Standard Text Protocol
#
详细的协议文档可以参考:https://github.com/memcached/memcached/blob/master/doc/protocol.txt
memcached 的标准文本协议是一个基于文本的协议,它使用 ASCII 字符串来进行通信。memcached 服务器监听在默认端口 11211 上,客户端通过 TCP 连接到服务器,然后发送命令和数据。因此我们可以很容易的通过 telnet 工具就可以完成 memcached 的基本操作。
...
December 17, 2024
这里不会过多的介绍软件的相关概念和架构,主要是针对实际问题的解决方案和思考。
问题汇总
#
-
CDC 相关
更新于: 2025-02-06
更新于:2025-10-11
-
DMS 数据同步相关
-
Istio 相关
-
APISIX 相关
-
ShardingSphere Proxy
-
Kafka 相关
...
August 18, 2024
ShardingSphere Proxy 是 Apache ShardingSphere 的一个子项目,是一个基于 MySQL 协议的数据库中间件,用于实现分库分表、读写分离等功能。在使用过程中,遇到了一些问题,记录如下。
这里主要针对的是 分库分表 的使用场景。
问题概述
#
数据库往往是一个系统最容易出现瓶颈的点,当遇到数据库瓶颈时,我们可以通过数据拆分来缓解问题。数据拆分的方式通常分为横向拆分和纵向拆分,横向拆分即分库分表;纵向拆分即把一个库表中的字段拆分到不同的库表中去。这两种手段并不互斥,而是在实际情况中相辅相成。本文即是横向拆分相关内容。
- 常见的部署方式有哪些?
- 数据分片规则怎么配置?
- 数据分片数应该怎么确定?
- 数据分片后唯一索引还有用吗?
- 数据分片后数据迁移?
- 数据分片后如何确定实际执行 SQL 语句?
- 数据分片后的查询优化?
0. 常见的部署方式
#
官方提供了两种部署方式:
- 单机部署:将 ShardingSphere Proxy 部署在单台服务器上,用于测试和开发环境。
- 集群部署:将 ShardingSphere Proxy 部署在多台服务器上,用于生产环境。集群模式下使用 zookeeper 来存储元数据。
关于元数据,元数据是 ShardingSphere Proxy 的核心,用于存储分库分表规则、读写分离规则等信息。
官方建议使用集群模式部署 生产环境的 ShardingSphere Proxy
如果不按照官方的指引,选择部署了多个 Standalone 模式的 ShardingSphere Proxy,那么需要注意“每个这样的 proxy 节点会有自己的元信息,他们之间并不互通”。在这些情况下会出现节点之间元数据不一致的问题,参看如下测试:
# 启动 3 个 standalone 模式的 ShardingSphere Proxy
+-------+
| LB |
+-------+
|
|-------------|--------------|
| | |
+-------+ +-------+ +-------+
| Node1 | | Node2 | | Node3 |
+-------+ +-------+ +-------+
初始表结构如下:
...
February 26, 2024
NATS设计与实现
#
https://github.com/nats-io/nats-sevrer
NATS 就是一个消息中间件,提供了 Pub/Sub 核心数据流,并基于此构建了 Request/Reply API 和 JetStream 用来提供可靠的分布式存储能力,和更高的 QoS(至少一次 + ACK)。
 ...
...