 May 8, 2025
May 8, 2025
本文主要解决在服务重构过程中如何保证新旧服务行为一致性的问题。
场景描述
#
现有一个 python 开发的 gRPC 微服务提供了一些 数据查询 接口 供 上层应用使用,随着业务流量的增加运维这个服务的成本也逐渐增加,为了降低运维成本和提高性能 (木有擅长 python 高性能的开发),因此选择了使用 go 语言对这个服务进行重写。在开发完成之后,需要对新服务的 gRPC 接口进行验证。
这种场景对测试开发人员来说,实在是太熟悉了吧?典型的 重放验证,马上能想到的验证手段就是:
- 如果有存量的单元测试,那么直接重新跑一遍单元测试就能快速的完成验证。
- 没有单元测试的情况,那么可以将新服务部署起来,通过流量复制的方式将旧服务的流量复制到新服务上,然后对比两个服务的返回结果是否一致。
flowchart LR
%% 定义布局方向和间距
subgraph s1["方案一: 单元测试验证"]
direction TB
UT[单元测试] -->|执行| NS1[新服务]
end
subgraph s2["方案二: 流量复制验证"]
direction TB
C[客户端] -->|请求| OS[旧服务]
OS -->|响应| C
OS -->|复制流量| NS2[新服务]
NS2 -->|对比响应| OS
end
%% 设置布局方向和对齐方式
s1 ~~~ s2
但是很遗憾 😭,并没有成熟的单元测试;测试人员也都是人肉测试,对于内部服务的接口验证帮助不大,因此这里采用第二种方式进行验证。
...
January 25, 2022
背景
#
gRPC 作为服务端的常用框架,它通过 protocol-buffers 语言来定义服务,同时也约定了请求和响应的格式,这样在服务端和客户端之间就可以通过 protoc 生成的代码直接运行而不用考虑编码传输问题了。
但是,可能会遇到这样的场景:
-
RPC 响应中 无用的字段过多 , 浪费带宽和无效计算,如下图所示:
这里的无用字段是指,在响应中,没有用到的字段,这些字段可以忽略掉,不会影响客户端的使用。
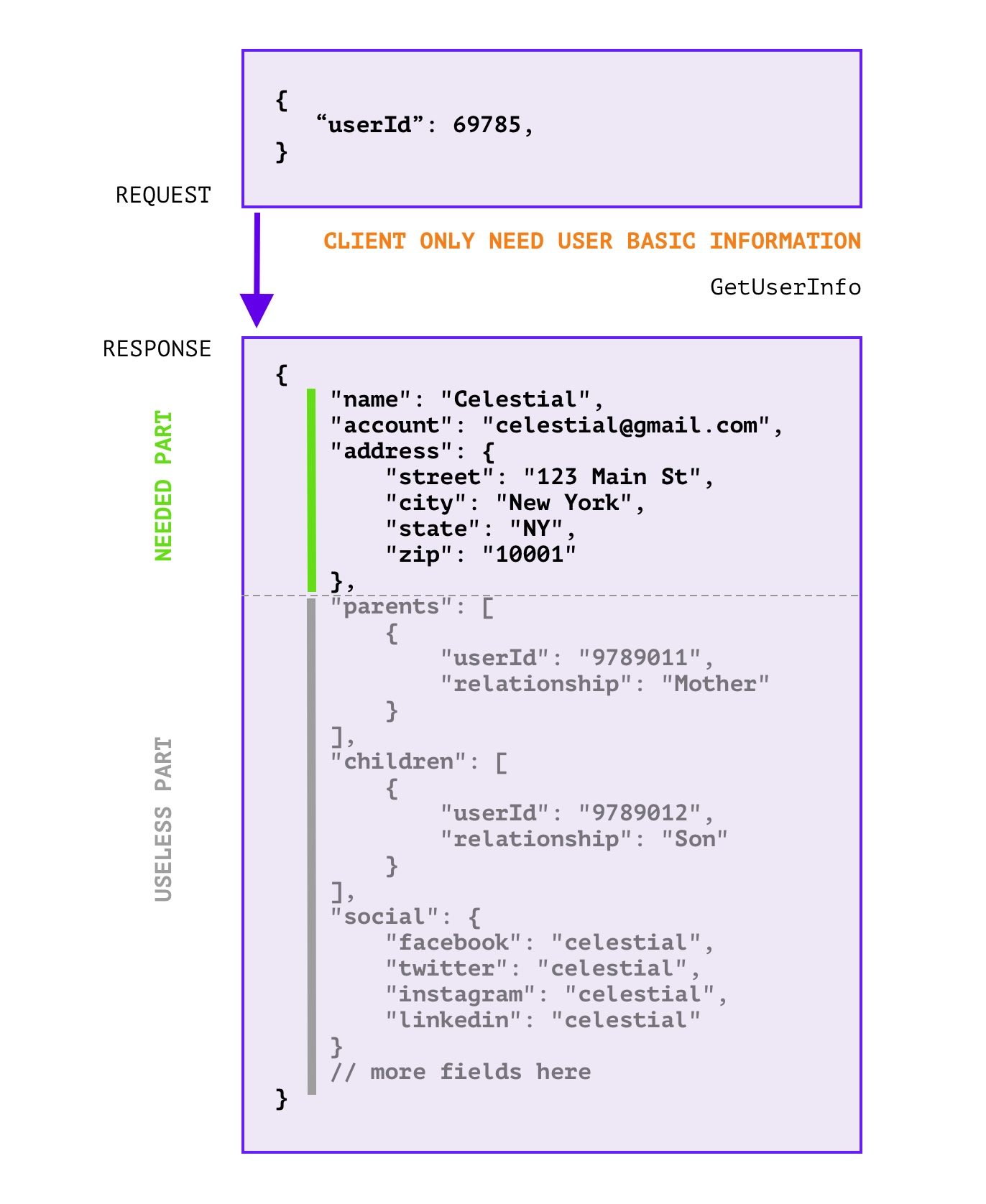
或许 拆分接口 是一个好的办法,但是可能会因为这样那样的原因(信息粒度降低导致接口太多了,有些地方就是需要聚合信息;细粒度的API设计同时会导致代码重复增加),可能无法推动拆分改造。同时如果没有拆分标准,亦或团队内成员不能严格遵守标准,那么拆分也只是重复问题而已。
-
RPC 增量更新时,如何判断零值字段是否需要更新?
对于 unset 和 zero value 不好区分的语言中(比如:go),在提供服务的一方遇到 增量更新 的场景时就会遇到这样的情况:
对于这种情况当然可以也有一些方法来解决,比如:使用指针来定义数据基本类型,那么在使用的时候如果判定为 nil 就说明没有设置,如果不为 nil 且为零值,那么就说明也是需要更新的。不过这样解决的缺点就是,nil refference panic 的概率又增加了,在使用时也稍微麻烦了一点。
 ·
·
解决方案
#
其实我们在思考上述两种场景的时候,把 客户端 和 服务端 的角色提取出来,就会发现这两个场景都是从 服务端 的视角遇到的问题,两个场景都是类似的:
- 客户端需要哪些字段,服务端不知道
- 客户端更新了哪些字段,服务端也不知道
但是,其实客户端是知道的,因此让客户端把这部分信息传递给服务端就行了。因此我们可以用 FieldMask 字段,用来传递客户端需要的字段,服务端就只返回需要的字段;客户端的告诉服务端需要哪些字段,服务端就更新哪些字段。
但是 FieldMask 只是一个定义,在具体的使用场景中还需要开发者自己编写一些辅助方法,来实现功能。那么是不是可以提供一个插件,让开发者可以只编写 proto 文件,便可以自动生成一些辅助方法呢?答案是肯定的,预览效果如下:
message UserInfoRequest {
string user_id = 1;
google.protobuf.FieldMask field_mask = 2 [
(fieldmask.option.Option).in = {gen: true},
(fieldmask.option.Option).out = {gen: true, message:"UserInfoResponse"}
];
}
message Address {
string country = 1;
string province = 2;
}
message UserInfoResponse {
string user_id = 1;
string name = 2;
string email = 3;·
Address address = 4;
}
message NonEmpty {}
service UserInfo {
rpc GetUserInfo(UserInfoRequest) returns (UserInfoResponse) {}
rpc UpdateUserInfo(UserInfoRequest) returns (NonEmpty) {}
}
生成的代码如下:
...
September 22, 2020
背景
#
第一次,线上遇到大量接口RT超过10s触发了系统告警,运维反馈k8s集群无异常,负载无明显上升。将报警接口相关的服务重启一番后发现并无改善。但是开发人员使用链路追踪系统发现,比较慢的请求总是某个gRPC服务中的几个POD导致,由其他POD处理的请求并不会出现超时告警。
第二次,同样遇到接口RT超过阈值触发告警,从k8s中查到某个gRPC服务(关键服务)重启次数异常,查看重启原因时发现是OOM Killed,OOM killed并不是负载不均衡直接导致的,但是也有一定的关系,这个后面再说。前两次由于监控不够完善(于我而言,运维的很多面板都没有权限,没办法排查)。期间利用pprof分析了该服务内存泄漏点,并修复上线观察。经过第二次问题并解决之后,线上超时告警恢复正常水平,但是该 deployment 下的几个POD占用资源(Mem / CPU / Network-IO),差距甚大。


第二张图是运维第一次发现该服务OOM killed 之后调整了内存上限从 512MB => 1G,然而只是让它死得慢一点而已。
从上面两张图能够石锤的是该服务一定存在内存泄漏。Go项目内存占用的分析,我总结了如下的排查步骤:
1. 代码泄漏(pprof)(可能原因 goroutine泄漏;闭包)
2. Go Runtime + Linux 内核(RSS虚高导致OOM)https://github.com/golang/go/issues/23687
3. 采集指标不正常(container_memory_working_set_bytes)
2,3 是基于第1点能基本排除代码问题的后续步骤。
解决和排查手段:
1. pprof 通过heap + goroutine 是否异常,来定位泄漏点
运行`go tool pprof`命令时加上--nodefration=0.05参数,表示如果调用的子函数使用的CPU、memory不超过 5%,就忽略它。
2. 确认go版本和内核版本,确认是否开启了MADV_FREE,导致RSS下降不及时(1.12+ 和 linux内核版本大于 4.5)。
3. RSS + Cache 内存检查
> Cache 过大的原因 https://www.cnblogs.com/zh94/p/11922714.html
// IO密集:手动释放或者定期重启
查看服务器内存使用情况: `free -g`
查看进程内存情况: `pidstat -rI -p 13744`
查看进程打开的文件: `lsof -p 13744`
查看容器内的PID: `docker inspect --format "{{ .State.Pid}}" 6e7efbb80a9d`
查看进程树,找到目标: `pstree -p 13744`
参考:https://eddycjy.com/posts/why-container-memory-exceed/
通过上述步骤,我发现了该POD被OOM killed还有另一个元凶就是,日志文件占用。这里就不过多的详述了,搜索方向是 “一个运行中程序在内存中如何组织 + Cache内存是由哪些部分构成的”。这部分要达到的目标是:一个程序运行起来它为什么占用了这么些内存,而不是更多或者更少。
...
January 17, 2020
由于保留必要的“罪证”,因此某些异常只能通过文字来描述了~
背景
#
昨晚上10点左右,前端童鞋反映开发环境接口响应超时,但过了几分钟后又恢复了,于是有了这一篇文章。
其实很久以前就出现了内存占用异常的情况~,只是占用并不高也就是50MB左右,加上当时还忙着写业务需求就没有急着加上pprof来检查。
首先通过运维平台(k8s based)直观发现了该pod数量从1变成了2, 再结合新增pod的启动时间,我发现该时间正好是前端童鞋反映状况的时间节点,稍后我检查了下该服务的资源限制如下图:

那么前端童鞋反映的问题就很明显了,由于某种原因导致了pod内存超限,触发了运维平台对于内存超限的“容忍机制”。表现为: 新增一个pod用于缓解服务压力,老服务由于无法申请更多内存会导致崩溃或其他异常(无法响应客户端请求),这与反映的情况一致。

pprof排查
#
知道了服务内存异常,想要具体定位的话,这时候就需要pprof上场了。
如果你需要重启服务才能开启pprof的话,那么只能等待复现了。这里我在开发环境和测试环境一直开启了pprof,因此可以直接检查。个人觉得,这样还可以帮助开发和测试,完成最初的性能分析😼。
内存检查
#
go tool pprof --http=:8080 https://service.host.com/debug/pprof/heap
这个命令是在本地打开一个web服务,直接可视化该服务的内存占用情况。也可以使用:
go tool pprof https://service.host.com/debug/pprof/heap 使用交互模式来分析。通过这个步骤定位到了 grpc相关的包内存占用异常分为两个部分:
50MB+ google.golang.org/grpc/internal/transport.newBufWriter
50MB+ bufio.NewReaderSize
http2 相关库的占用也比较多
这一切都指向了我们使用的gRPC,可是为啥使用gRPC会用到这么“多”内存呢?接着分析
goroutine检查
#
打开一看 https://service.host.com/debug/pprof/一看,goroutine和heap居“高”(4000+)不下,虽然对于动辄10W+的别人家的服务来说,这点根本不算事,但在我们这种小作坊里可就算异常了。点开看goroutine查看详情,有四个部分的goroutine分别有900个左右,这里就算初步定位了“gRPC客户端使用了较多的goroutine,但是却没有正确的结束掉”,如下图(这是解决后的截的图):

pprof总结
#
服务中使用的gRPC客户端出了某些故障,导致了goroutine泄漏,引发了OOM(Out Of Memory)。如下图:
代码排查
#
上一步已经定位到是gRPC客户端的问题,那么就可以直接从代码上手了。我心里已经有一个“嫌疑犯”了,如下:
var (
defaultHandler *handler
timeout = 5 * time.Second
// _ pb.UserServiceClient = &handler{}
)
// Init of usersvc.handler
func Init(rpcAddr string) error {
// ... 略去不表
}
type handler struct {
// rpc configs
rpcAddr string
client pb.UserServiceClient
lastGrpcReqError error
}
func (h *handler) connectRPC() {
if h.client != nil && h.lastGrpcReqError != nil {
// 这里判断的本意是:如果客户端初始化失败,
// 或者期间因为异常情况,导致客户端与服务端连接中断的情况下尝试重连。
//
// 但是忽略了gRPC实现中,对于客户端的处理:
// 1. grpc.Dail 是异步的
// 2. grpc 有自己的重连机制
//
// 这一部分我还没有看完,就不乱发表看法了。
conn, err := grpc.Dial(h.rpcAddr, grpc.WithInsecure())
if err != nil {
logger.Std.Errorf("could not dial: %s with err: %v", h.rpcAddr, err)
return
}
logger.Std.Infof("usersvc.client.connectRPC called")
h.client = pb.NewUserServiceClient(conn)
}
}
// QueryBasicInfoByID based default Handler .
func QueryBasicInfoByID(in *pb.ByIDForm) (*pb.BasicInfoResponse, error) {
defaultHandler.connectRPC()
ctx, cancel := context.WithTimeout(context.Background(), timeout)
defer cancel()
resp, err := defaultHandler.client.QueryBasicInfoByID(ctx, in)
defaultHandler.lastGrpcReqError = err
return resp, err
}
抛开本意不谈,这样的写法也是不OK的。。。因为
...