 September 21, 2019
September 21, 2019
一些名词
#
MTU(Maximum Transmission Unit)
#
the maximum transmission unit (MTU) is the size of the largest protocol data unit (PDU) that can be communicated in a single network layer transaction. ——from wiki
MTU 物理接口(数据链路层)提供给其上层(通常是IP层)最大一次传输数据的大小。一般来说MTU=1500byte。如果MSS + TCP首部 + IP首部 > MTU,那么IP报文就会存在分片,否则就不需要分片。
MSS (Maximum Segment Size)
#
The maximum segment size (MSS) is a parameter of the options field of the TCP header that specifies the largest amount of data, specified in bytes, that a computer or communications device can receive in a single TCP segment. ——from wiki
...
April 1, 2019
Golang编写的热重载工具,自定义命令,支持监视文件及路径配置,环境变量配置。这是一个重复的轮子~
安装使用
#
go install github.com/yeqown/go-watcher/cmd/go-watcher
命令行
#
➜ go-watcher git:(master) ✗ ./go-watcher -h
NAME:
go-watcher - A new cli application
USAGE:
go-watcher [global options] command [command options] [arguments...]
VERSION:
2.0.0
AUTHOR:
[email protected]
COMMANDS:
init generate a config file to specified postion
run execute a command, and watch the files, if any change to these files, the command will reload
help, h Shows a list of commands or help for one command
GLOBAL OPTIONS:
--help, -h show help
--version, -v print the version
配置文件
#
watcher: # 监视器配置
duration: 2000 # 文件修改时间间隔,只有高于这个间隔才回触发重载
included_filetypes: # 监视的文件扩展类型
- .go #
excluded_regexps: # 不被监视更改的文件正则表达式
- ^.gitignore$
- '*.yml$'
- '*.txt$'
additional_paths: [] # 除了当前文件夹需要额外监视的文件夹
excluded_paths: # 不需要监视的文件名,若为相对路径,只能对于当前路径生效
- vendor
- .git
envs: # 额外的环境变量
- GOROOT=/path/to/your/goroot
- GOPATH=/path/to/your/gopath
使用范例日志
#
➜ go-watcher git:(master) ✗ ./package/osx/go-watcher run -e "make" -c ./config.yml
[INFO] directory (/Users/yeqown/Projects/opensource/go-watcher) is under watching
[INFO] directory (/Users/yeqown/Projects/opensource/go-watcher/cmd) is under watching
[INFO] directory (/Users/yeqown/Projects/opensource/go-watcher/cmd/go-watcher) is under watching
[INFO] directory (/Users/yeqown/Projects/opensource/go-watcher/internal) is under watching
[INFO] directory (/Users/yeqown/Projects/opensource/go-watcher/internal/command) is under watching
[INFO] directory (/Users/yeqown/Projects/opensource/go-watcher/internal/log) is under watching
[INFO] directory (/Users/yeqown/Projects/opensource/go-watcher/internal/testdata) is under watching
[INFO] directory (/Users/yeqown/Projects/opensource/go-watcher/internal/testdata/exclude) is under watching
[INFO] directory (/Users/yeqown/Projects/opensource/go-watcher/internal/testdata/testdata_inner) is under watching
[INFO] directory (/Users/yeqown/Projects/opensource/go-watcher/package) is under watching
[INFO] directory (/Users/yeqown/Projects/opensource/go-watcher/package/archived) is under watching
[INFO] directory (/Users/yeqown/Projects/opensource/go-watcher/package/linux) is under watching
[INFO] directory (/Users/yeqown/Projects/opensource/go-watcher/package/osx) is under watching
[INFO] directory (/Users/yeqown/Projects/opensource/go-watcher/resources) is under watching
[INFO] directory (/Users/yeqown/Projects/opensource/go-watcher/utils) is under watching
[INFO] directory (/Users/yeqown/Projects/opensource/go-watcher/utils/testdata) is under watching
[INFO] directory (/Users/yeqown/Projects/opensource/go-watcher/utils/testdata/testdata_inner) is under watching
rm -fr package
go build -o package/osx/go-watcher cmd/go-watcher/main.go
GOOS=linux GOARCH=amd64 go build -o package/linux/go-watcher cmd/go-watcher/main.go
mkdir -p package/archived
tar -zcvf package/archived/go-watcher.osx.tar.gz package/osx
a package/osx
a package/osx/go-watcher
tar -zcvf package/archived/go-watcher.linux.tar.gz package/linux
a package/linux
a package/linux/go-watcher
[INFO] command executed done!
[INFO] (/Users/yeqown/Projects/opensource/go-watcher/package/osx/go-watcher) is skipped, not target filetype
[INFO] (/Users/yeqown/Projects/opensource/go-watcher/package/osx) is skipped, not target filetype
[INFO] (/Users/yeqown/Projects/opensource/go-watcher/package) is skipped, not target filetype
[INFO] (/Users/yeqown/Projects/opensource/go-watcher/package/linux/go-watcher) is skipped, not target filetype
[INFO] (/Users/yeqown/Projects/opensource/go-watcher/package/linux) is skipped, not target filetype
[INFO] (/Users/yeqown/Projects/opensource/go-watcher/package/archived/go-watcher.linux.tar.gz) is skipped, not target filetype
[INFO] (/Users/yeqown/Projects/opensource/go-watcher/package/archived) is skipped, not target filetype
[INFO] (/Users/yeqown/Projects/opensource/go-watcher/VERSION) is skipped, not target filetype
[INFO] [/Users/yeqown/Projects/opensource/go-watcher/cmd/go-watcher/main.go] changed
rm -fr package
mkdir -p package/osx
mkdir -p package/linux
echo "2.0.0" > VERSION
cp VERSION package/osx
cp VERSION package/linux
go build -o package/osx/go-watcher cmd/go-watcher/main.go
GOOS=linux GOARCH=amd64 go build -o package/linux/go-watcher cmd/go-watcher/main.go
mkdir -p package/archived
tar -zcvf package/archived/go-watcher.osx.tar.gz package/osx
a package/osx
a package/osx/go-watcher
a package/osx/VERSION
tar -zcvf package/archived/go-watcher.linux.tar.gz package/linux
a package/linux
a package/linux/go-watcher[INFO] (/Users/yeqown/Projects/opensource/go-watcher/package/osx) is skipped, not target filetype
[INFO] (/Users/yeqown/Projects/opensource/go-watcher/package/linux) is skipped, not target filetype
a package/linux/VERSION
[INFO] command executed done!
[INFO] (/Users/yeqown/Projects/opensource/go-watcher/package/osx) is skipped, not target filetype
[INFO] (/Users/yeqown/Projects/opensource/go-watcher/package/archived) is skipped, not target filetype
[INFO] (/Users/yeqown/Projects/opensource/go-watcher/package) is skipped, not target filetype
[INFO] (/Users/yeqown/Projects/opensource/go-watcher/VERSION) is skipped, not target filetype
[INFO] (/Users/yeqown/Projects/opensource/go-watcher/package) is skipped, not target filetype
^C[INFO] quit signal captured!
[INFO] go-watcher exited
➜ go-watcher git:(master) ✗
June 28, 2018
“熟悉http协议”,肯定很多IT小伙伴都在招聘岗位上看得到过,但是怎么才叫熟悉http协议呢?抽空梳理了一下,也算是对这一部分知识的笔记吧!
可能对于大部分人来说,网络web编程就是使用一些第三方库来进行请求和响应的处理,再多说一点就是这个URI要使用POST方法,对于携带的数据需要处理成为formdata。
基础知识
#
Q1: HTTP协议是什么?用来干什么?
HTTP协议是基于TCP/IP协议的应用层协议,主要规定了客户端和服务端之间的通信格式。主要作用也就是传输数据(HTML,图片,文件,查询结果)。
#网络分层
#
互联网的实现分成了几层,如何分层有不同的模型(七层,五层,四层),这里按五层模型来解释:
(靠近用户)应用层 < 传输层 < 网络层 < 链接层 < 物理层(靠近硬件)
| 层级 |
作用 |
拥有协议 |
| 物理层 |
传送电信号0 1 |
无 |
| 数据链路层 |
定义数据包;网卡MAC地址;广播的发送方式; |
Ethernet 802.3; Token Ring 802.5 |
| 网络层 |
引进了IP地址,用于区分不同的计算机是否属于同一网络 |
IP; ARP; RARP |
| 传输层 |
建立端口到端口的通信,实现程序时间的交流,也就是socket |
TCP; UDP |
| 应用层 |
约定应用程序的数据格式 |
HTTP; FTP; DNS |
每一层级,都是解决问题而诞生的,也就是他们各自作用对应的问题,推荐参考资料中的“互联网协议入门”。
#HTTP通信流程
#

#拓展–三次握手和四次挥手
#
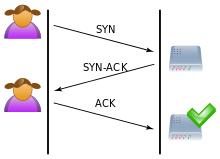
经常在其他地方看到这些,一直不知道了解这部分有什么用,但是syn Flood攻击,恰恰是利用了TCP三次握手中的环节。利用假IP伪造SYN请求,服务端会多次尝试发送SYN-ACK给客户端,但是IP并不存在也就无法成功建立连接。在一定时间内伪造大量这种请求,会导致服务器资源耗尽无法为正常的连接服务。(注:服务器SYN连接数量有限制,SYN-ACK超时重传机制)
三次握手流程:
- The client requests a connection by sending a SYN (synchronize) message to the server.
- The server acknowledges this request by sending SYN-ACK back to the client.
- The client responds with an ACK, and the connection is established.
...
June 8, 2018
背景和目标
#
背景
#
项目需要在现有项目的基础上实现权限系统,但为了低耦合,选择实现了一个基于ne7ermore/gRBAC的auth-server,用于实现权限,角色,用户的管理,以及提供鉴权服务。在开发环境对接没有问题,正常的鉴权访问。到了线上部署的时候,才发现:
- 线上某服务部署在多台机器上;
- 目前的api-gateway并不支持同一服务配置多个node;
想的办法有:
| 序号 |
描述 |
优点 |
缺点 |
| 1 |
api-gateway通过url来转发请求,之前是配置IP加端口 |
api-gateway改动小 |
影响web和APP升级 |
| 2 |
api-gateway能支持多台机器,并进行调度 |
api-gateway功能更强大,把以后要做的事情提前做好基础 |
好像没啥缺点,只是费点时间支持下多节点配置,并调度 |
如果没说清,请看下图:
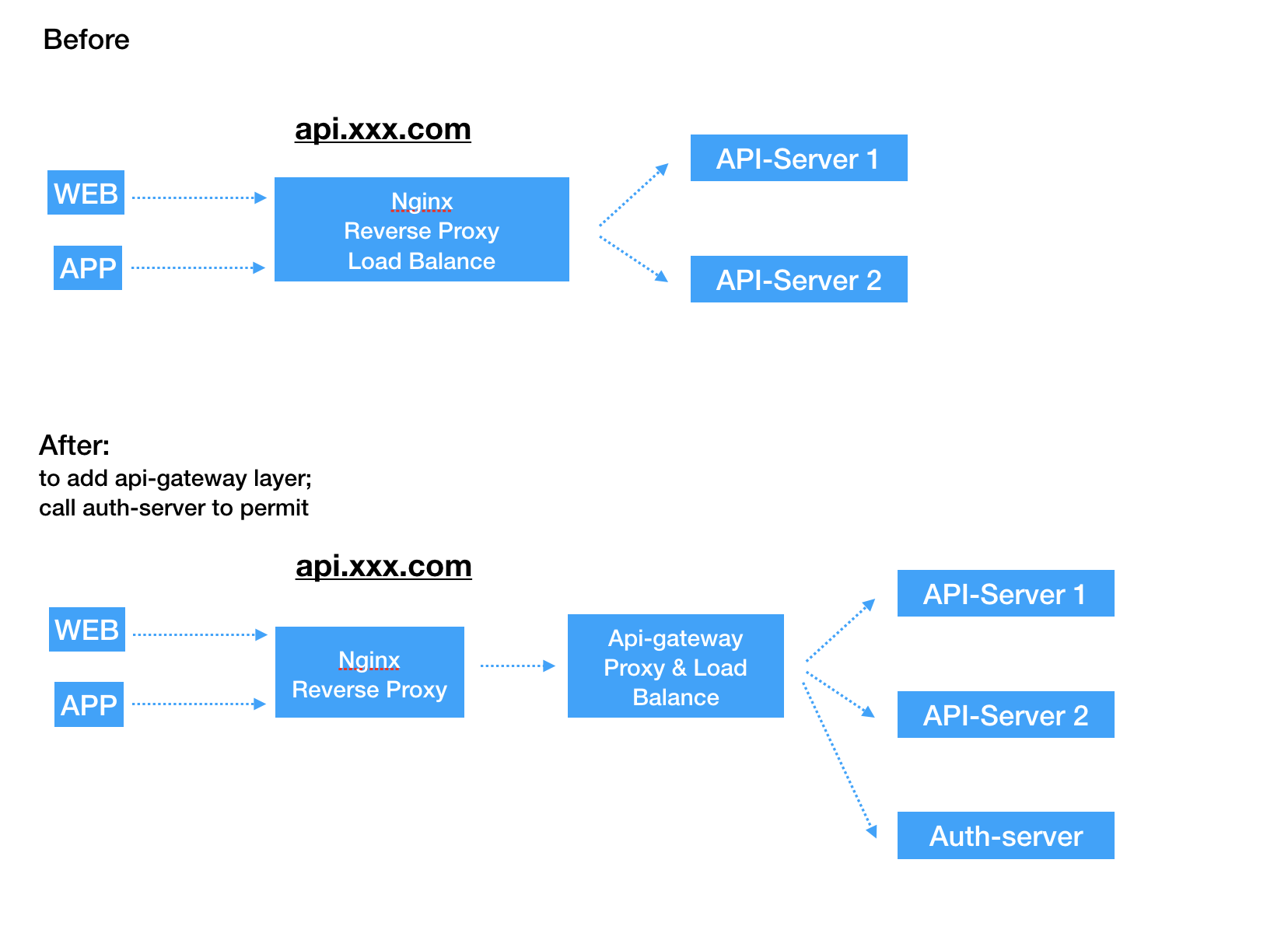
目标
#
那么,目标也就明确了,需要实现api-gateway中实现基于权重的调度。为啥要基于权重?其一是仿照nginx基于权重的负载均衡,其二是服务器性能差异。
轮询调度算法介绍
#
轮询调度算法:
#
轮询调度算法的原理是每一次把来自用户的请求轮流分配给内部中的服务器,从1开始,直到N(内部服务器个数),然后重新开始循环。该算法的优点是其简洁性,它无需记录当前所有连接的状态,所以它是一种无状态调度。
假设有一组服务器N台,S = {S1, S2, …, Sn},一个指示变量i表示上一次选择的服务器ID。变量i被初始化为N-1。其算法如下:
j = i;
do {
j = (j + 1) mod n;
i = j;
return Si;
} while (j != i);
return NULL;
平滑加权轮询调度算法:
#
上述的轮询调度算法,并没有考虑服务器性能的差异,实际生产环境中,每一台服务器配置和安装的业务并不一定相同,处理能力不完全一样。因此需要根据服务器能力,分配不同的权值,以免服务的超负荷和过分闲余。
...
May 18, 2018
需要的技术及工具:
- Python3 + Selenuium
- Golang net/http
- React-Native 相关(使用了react-navigation)
- MongoDB
- Redis
代码地址:
项目构思及构成
#
食谱类型的App,应用市场肯定有更好的的食谱APP。所以自己开发的目的,首先是写代码,其次是定制APP~
好的,现在化身产品经理,设计一下APP有哪些功能:
- 每日菜谱推荐,推荐可更换
- 每天需要准备的材料提醒
- 发现更多菜谱
- 分类筛选菜谱
- 搜索菜谱
- 查看菜谱详情
- 设置(不知道设置啥,提前准备吧)
设计稿?不存在的,随心所欲。
现在分析下我需要做的事情:
- 能跑起来的APP,与restful web api 交互。
- 能跑起来的web-api,提供菜谱数据,筛选,推荐,搜索等功能
- 能跑起来的简易spider,从网上获取菜谱信息。(这个爬虫能解析动态生成网站就够用了,姑且称之为爬虫吧)
没有考虑大量数据,因此爬虫并不通用,只适合特定XX网站。
实战爬虫
#
这个APP里面最重要的就是菜谱数据了,那么开发之前,需要明确的数据格式,如下:
{
"name": "name",
"cat": "cat",
"img": "img_url",
"mark_cnt": 19101,
"view_cnt": 181891,
"setps": [
{
"desc": "",
"img": "",
},
// more step
],
"material": {
"ingredients": [
{
"name": "ingredients_name",
"weight": "ingredients_weight",
},
// more ingredients
],
"seasoning": [
{
"name": "seasoning_name",
"weight": "seasoning_weight",
},
// more seasoning
],
},
"create_time": "2018xxxxxx",
"update_time": "2018xxxxxx",
}
目标
#
前提:无法直接获取到该网站的服务API,才使用爬虫间接获取数据。
...
April 20, 2018
关于Gorm
#
gorm文档
遇见问题
#
无法通过结构体的方式更新或查询零值
#
这里零值是说,各个类型的默认值。
关于这一点是在这里中注明了的,也提供了解决方案:
WARNING when update with struct, GORM will only update those fields that with non blank value
For below Update, nothing will be updated as “”, 0, false are blank values of their types
NOTE When query with struct, GORM will only query with those fields has non-zero value, that means if your field’s value is 0, ‘’, false or other zero values, it won’t be used to build query conditions,
...
April 8, 2018
目录
#
Channel
#
一开始是在看channel的源码,结果发现里面含有一些抽象的描述(可能也就是我觉得。。。毕竟没有深入)
Do not change another G’s status while holding this lock
(in particular, do not ready a G), as this can deadlock
with stack shrinking.
其中G是啥?我看着是很懵逼的,去google了一下,其实是goroutine相关的知识,那就把goroutine理解了先。
2020-04-13 填坑
channel in go
Goroutine
#
G: 表示goroutine,存储了goroutine的执行stack信息、goroutine状态以及goroutine的任务函数等;另外G对象是可以重用的。
P: 表示逻辑processor,P的数量决定了系统内最大可并行的G的数量(前提:系统的物理cpu核数>=P的数量);P的最大作用还是其拥有的各种G对象队列、链表、一些cache和状态。
M: 代表着真正的执行计算资源。在绑定有效的p后,进入schedule循环;而schedule循环的机制大致是从各种队列、p的本地队列中获取G,切换到G的执行栈上并执行G的函数,调用goexit做清理工作并回到m,如此反复。M并不保留G状态,这是G可以跨M调度的基础。M必须关联了P才能执行Go代码。
结合下图更方便理解: –源于Tonybai的博客,见参考资料。

参考资料
#
March 2, 2018
本文主要是总结下在使用aliyun-rds数据备份方案过程中的心得。
高可用一直都是线上服务维护用户体验的关键之一。为了达到高可用,业界已经有了很多方案。最典型的就是“冗余备份+自动故障转移”。冗余备份是说,当一个节点服务不可用时,有其他服务能够代替其工作。除此之外,如果服务出现了必须人工介入解决的故障,也会影响系统的高可用特性。
本文着重介绍数据的高可用方案
数据库冗余
#
如果是单节点的数据库,还用的着说吗?要保证服务高可用,除了主-从数据库之外,还需要从备份数据库,当然不能保证说一定不会遇到所有的备份数据库,都挂掉的情况…。阿里云提供了RDS-高可用版本和RDS-单机版,两者的区别见下图:
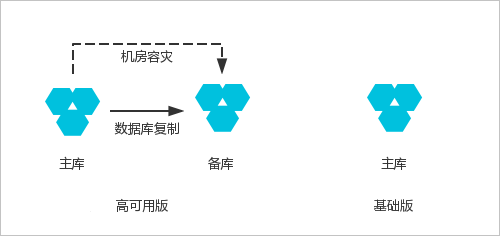 这就算最基本的冗余了,没有主从复制,没有读写分离。但是能保证主库在换掉的时候,还能使用备库提供服务。如果服务对于数据库性能和可用性有一定要求,那么可以在这个基础上升个级,见下图:
这就算最基本的冗余了,没有主从复制,没有读写分离。但是能保证主库在换掉的时候,还能使用备库提供服务。如果服务对于数据库性能和可用性有一定要求,那么可以在这个基础上升个级,见下图:
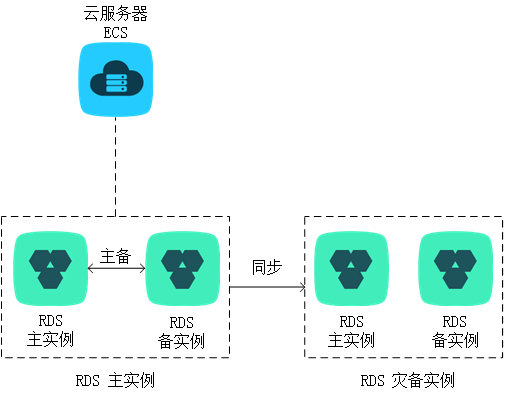
数据故障自动转移
#
已经有了冗余的数据库节点了,那么接下来要做的事情就是怎么感知数据库异常,并实现自动切换到备份实例中? 阿里云灾备方案的文档是这样描述的:
主实例和灾备实例均搭建主备高可用架构,当主实例所在区域发生突发性自然灾害等状况,主节点(Master)和备节点(Slave)均无法连接时,可将异地灾备实例切换为主实例,在应用端修改数据库链接地址后,即可快速恢复应用的业务访问。
对于主节点全部不可用的情况对应用服务是可见的,因此应用服务可以通过指定一些异常判断,在判定主节点不可用的时候,主动切换数据库连接地址来获取数据,提供服务。
// sql-detect.go
package main
import (
"database/sql"
"fmt"
"sync"
"time"
_ "github.com/go-sql-driver/mysql"
_ "github.com/mxk/go-sqlite"
)
var (
mysqlAvailable bool = true
mutex = sync.Mutex{}
db *sql.DB = nil
)
func MysqlDetection(db *sql.DB, ticker *time.Ticker) {
for {
select {
case <-ticker.C:
if e := db.Ping(); e != nil {
fmt.Println("got error", e)
mutex.Lock()
mysqlAvailable = false
mutex.Unlock()
} else {
fmt.Println("status ok")
}
}
}
}
func MysqlSwitch() {
for {
mutex.Lock()
if !mysqlAvailable {
fmt.Println("Switch Sqlite3")
db, _ = sql.Open("sqlite3", "./foo.db")
}
mutex.Unlock()
time.Sleep(time.Second * 4)
}
}
func main() {
c := make(chan bool)
db, _ = sql.Open("mysql", "yeqiang:yeqiang@/test_yeqiang")
ticker := time.NewTicker(time.Second * 2)
go MysqlDetection(db, ticker)
go MysqlSwitch()
<-c
}
测试截图:
...
January 29, 2018
在知乎上看了一个很有启发的回答,因此实际动手来实现短URL生成系统。贴上链接:
知乎 - 短URL系统是如何设计的。其中提到了,要实现短URL生成系统要解决的问题有:
- 如何优雅的实现?
- 怎么基本实现长对短、一对一?
- 如何实现分布式,高并发,高可用?
- 储存选用?
基本原理
#
数据库自增ID转换62进制
- 使用自增ID不会产生重复的短链接。
- 为了解决自增ID超长和不便记忆,对ID进行62进制编码。所谓62进制就是0-9,a-z,A-Z。
简单计算下:
62 ^ 4 = 14,776,336
62 ^ 5 = 916,132,832
62 ^ 6 = 56,800,235,584 // 已经足够使用了
总体结构及处理流程
#
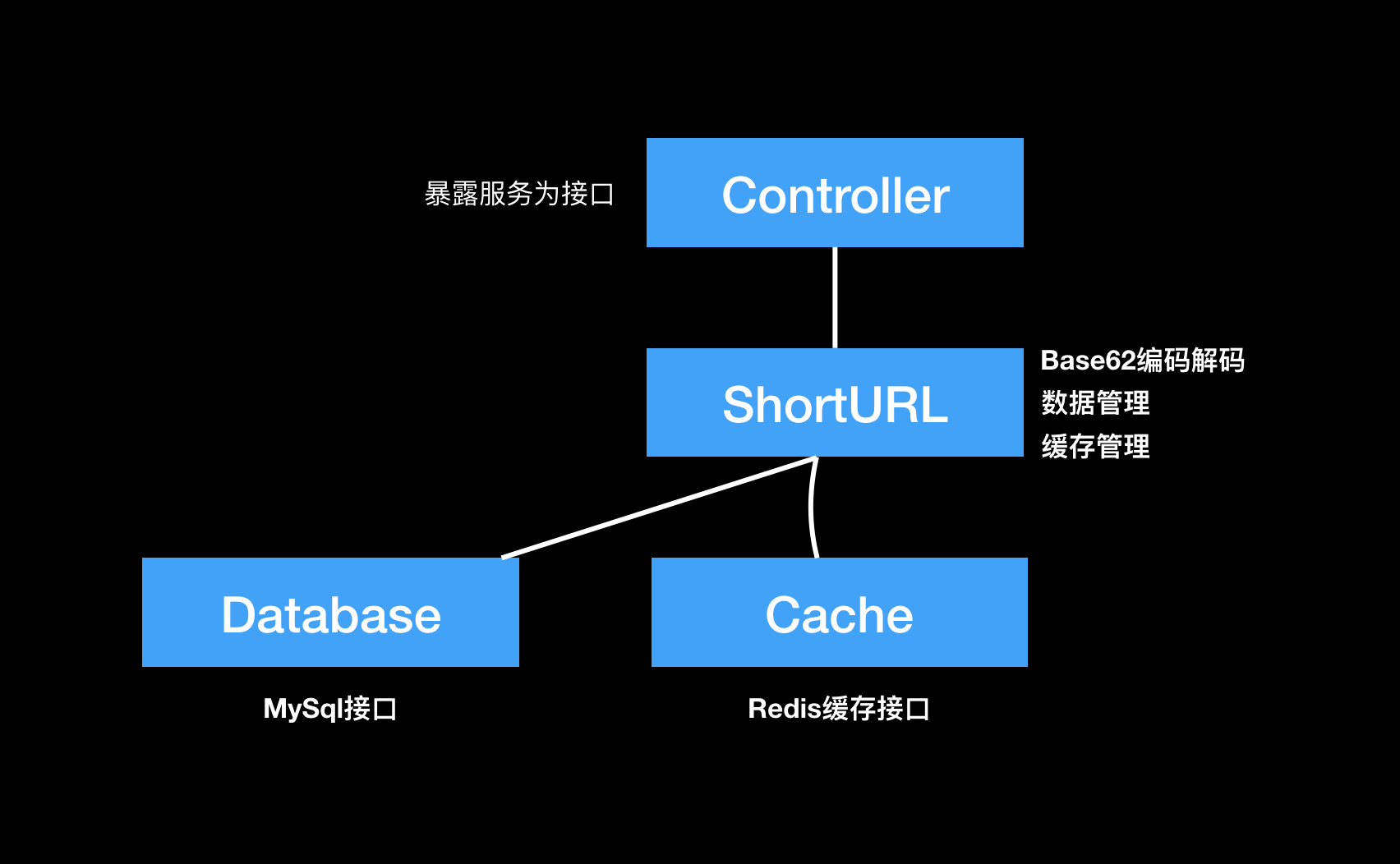
长链接处理流程
#
- 获取参数,调用shortURL服务
- 尝试从缓存中获取,如果命中,则读取短链接(重置过期时间)。跳转第4步
- 将长链接存储到Mysql数据库,根据ID进行base62编码,组装Domain+Encoded字符串并更新数据库
- 返回生成的短链接
短链接处理流程
#
- 解析短链接为ID
- 查询ID对应的长链接
- 以301方式跳转到长链接
长链接与短链接的对应关系
#
一对多,一个长链接可能对应多个短链接。数据表存储结构如下:
+-----------+--------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-----------+--------------+------+-----+---------+----------------+
| id | int(64) | NO | PRI | NULL | auto_increment |
| long_url | varchar(100) | NO | | NULL | |
| short_url | varchar(40) | YES | | NULL | |
+-----------+--------------+------+-----+---------+----------------+
分布式和高并发设计
#
###注:这部分未实现。我的思路如下:
...
January 27, 2018
总结使用Golang开发服务端时,使用的基础的工具和部署方式。用于思考不足并优化,提升编码效率。
总体上采用MVCS的软件模式,如下图:
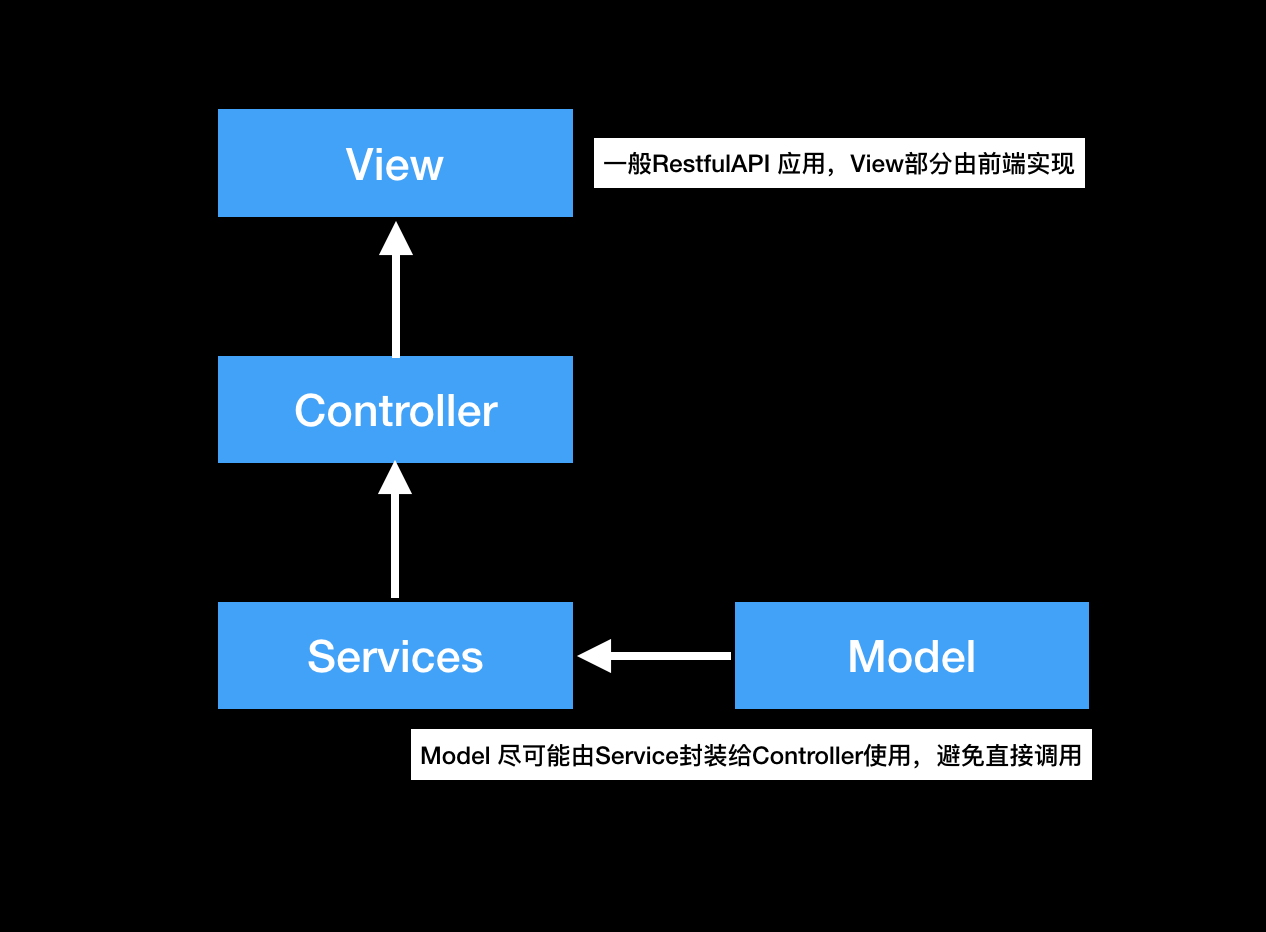
从图中可以看出,MVCS是从MVC进化而来,相比于MVC,增加了Service层。把业务逻辑从Controller层中抽离出来,这样做的好处在于,项目日益庞大之后,将某些功能独立出来。
Golang工具
#
“gvt” 依赖管理工具
“httprouter” 路由及中间件配置
“schema” 解析请求参数到结构体
“beego/validation” 结构体校验工具
“github.com/go-redis/redis” redis操作库
“github.com/go-sql-driver/mysql” Mysql Driver
文件结构
#
--Golang Project
|-sh # shell脚本,包括数据库脚本
|-config # 配置文件
|-logs # 日志文件
|-vendor # 项目源码及依赖
| |-github.com #
| |-mainfest # gvt 依赖管理文件
| |-app
| |-utils
| |-controllers
| |-models
| |-route
| |-services
|-Dockerfile # docker构建镜像配置文件
|-docker-compose.yml # docker-compose.yml文件
`-entry.go # web服务入口文件
部署方式
#
采用docker来部署应用。分别编写Dockerfile和docker-composer.yml文件,实例如下:
...