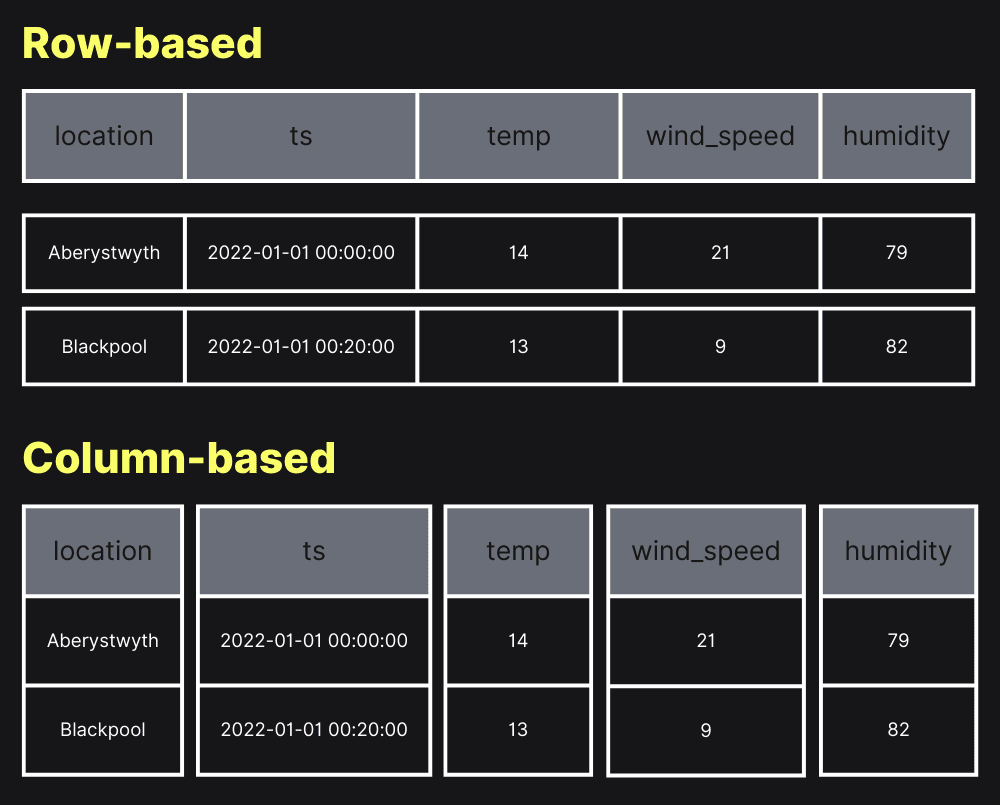
列式数据库与行式数据库最大的区别在于数据的存储方式,也就是它们在磁盘上的组织方式不同。传统的行式数据库常用于 OLTP (Online Transaction Processing) 场景,在这个场景下需要频繁的进行数据的插入、更新、删除操作,操作的对象往往是单行数据。而列式数据库常用于 OLAP (Online Analytical Processing) 场景,对于数据的聚合查询更为常见,往往需要扫描某一列的大量数据进行计算。
如果同时用过两种类型的数据库,就会发现:
这里列举的优化原则只是冰山一角,仅用于说明两种数据库最显眼的差异。
使用行式数据库过程中,最简单常见的优化原则就是 尽可能命中索引、降低 B+ 树高度、减少扫描行数,如:
- 优先对区分度高的列建立索引
- 覆盖索引(索引中包含查询所需的所有列,避免回表)
- 索引下推(在存储引擎层提前过滤不满足条件的数据)
- 最左前缀匹配原则
- 避免使用函数或者隐式类型转换(如:
where date(create_time) = '2022-01-01'),会导致索引失效 - 避免在索引列上使用
!=、<>等操作符,会导致索引失效 - 避免深度分页
- 分库分表(提出这一优化方向,也是基于单表数据量过大,索引维护的开销会增加,性能也会退化)
- 等等…
减少扫描行数这一思路对于列式数据库同样适用(如分区裁剪),但列式数据库还有另一个很重要的优化方向,那就是 减少列,如:
- 行存特性(如果是点查询,列数据库 I/O 反而会增加,这一点和行式数据库正好相悖)
- 只读取查询涉及的列(行存也提倡避免 SELECT *,但由于行存以行为单位读取磁盘,主要减少的是网络传输量而非磁盘 I/O;而列存中每列独立存储,少读一列就直接少一份磁盘 I/O)
- 等等…
当然,任何数据库的优化,都逃不开 减少 I/O 这一核心目的。说得更白话一点,如果有一种完美的存储介质,它没有I/O延迟,也不会丢失数据,那么这些优化也就不再需要了。
1. ClickHouse 的设计#
1.1 整体组件#
从 ClickHouse 的架构图来看,列式数据库包含以下核心组件:
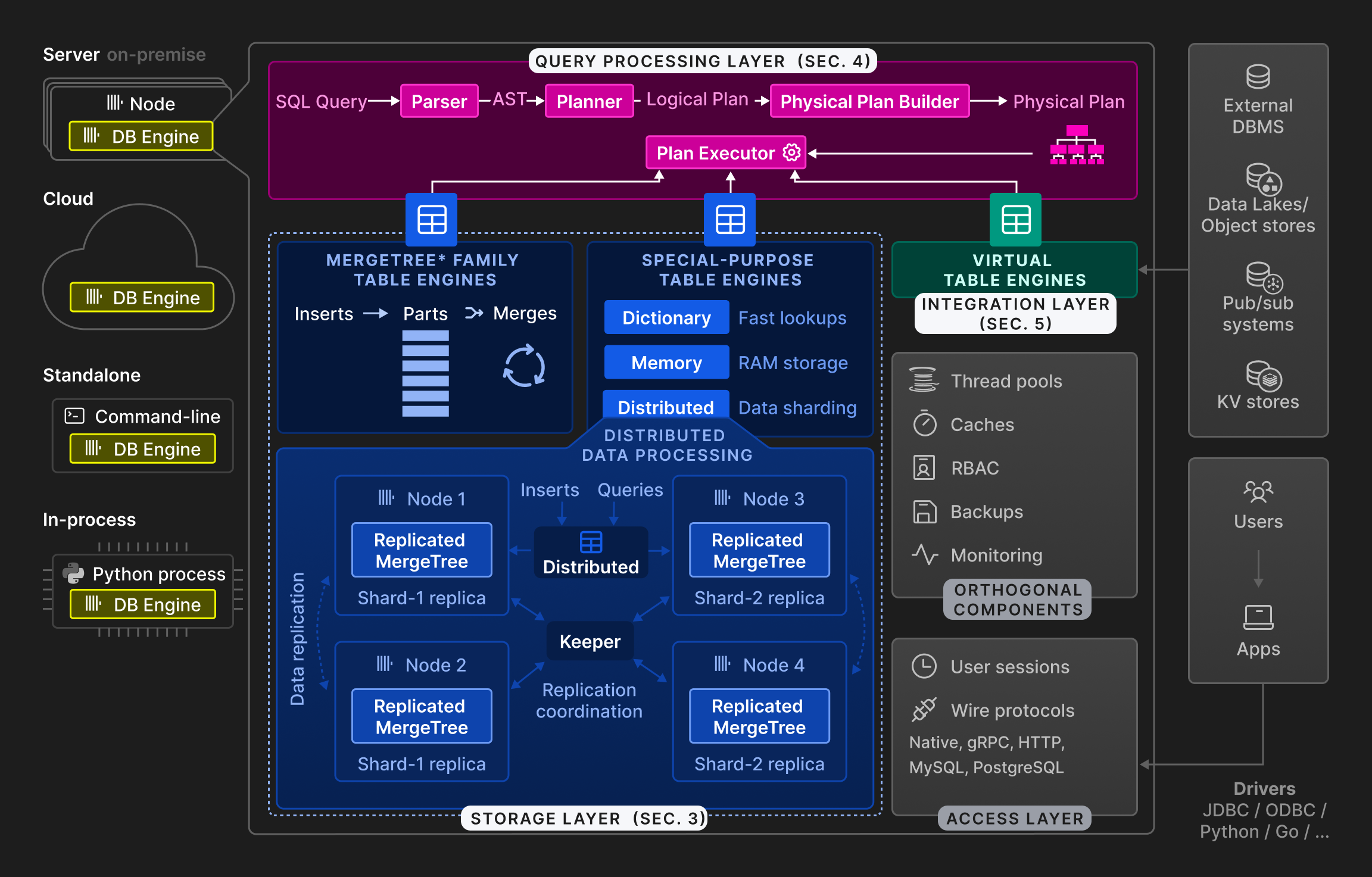
- 查询处理层: 查询处理遵循传统范式:解析入站查询、构建并优化逻辑与物理查询计划,然后执行
- SQL Parser
- SQL Planner
- Physical Plan Builder
- Plan Executor
- 存储层:由不同的表引擎组成,这些表引擎封装了表数据的格式和位置
- MergeTree* Family Tables Engines: 代表了 ClickHouse 中的主要持久化格式
- Special-Purpose Tables Engines:用于加速或分布查询执行的专用表引擎
- Dictionary
- Memory
- Distributed (Data Sharding) 处理分布式
- 集成层:用于与外部系统进行双向数据交换的虚拟表引擎,例如关系型数据库 (如 PostgreSQL、MySQL) 、发布/订阅系统 (如 Kafka、RabbitMQ) ,或键值存储 (如 Redis) 。还可以与数据湖 (如 Iceberg) 或对象存储中的文件 (如 AWS S3、Google GCP) 交互
- Virtual Tables Engines
- 正交组件:提供辅助功能
- Thread pools
- Caches
- RBAC (Role-Based Access Control)
- Backups
- Monitoring
- 访问层:通过不同协议管理用户会话并与应用程序通信
- User Session
- Wire protocols
我们更进一步,丢掉分布式特性、集成和监控,只保留最影响 OLAP 查询性能的核心设计,如下所示:
| 层 | 组件 | 职责 |
|---|---|---|
| 查询处理层 | SQL Parser | 解析 SQL 语句,生成抽象语法树 (AST) |
| 查询处理层 | Query Engine | 查询计划生成、优化和执行,即 ClickHouse 中的 SQL planner、Physical Plan Builder、Plan Executor 集成 |
| 存储层 | MergeTree Engine | 列式存储格式、数据分块、压缩编码、稀疏索引、Data Skipping Index、数据读写 |
查询处理层本身非常复杂,这里不展开;下面会从存储结构、写入路径、查询裁剪和系统级取舍几个角度,拆开看 ClickHouse 为 OLAP 做了哪些核心设计。
1.2 存储结构#
列式数据库通常有如下的特点(相较于行式数据库而言):
- 压缩率高
- 大数据集的聚合计算更快
- 按列过滤高效
- 并行度高
- 更新 / 删除 性能较差
- 点查询 性能较差
而这些特点跟它的存储结构紧密相关。
ClickHouse 中每个 MergeTree* 表引擎的表都被组织为一组不可变的表分片,每当一批行数据插入到表中时,会创建一个分片。后台合并任务会定期将多个小分片合并成一个大分片,直到达到可配置的分片大小。因此为了提升写入性能(减少分片数量),行数据插入支持两种模式:
- 同步模式:每条 INSERT 创建一个新的分片 (因此建议客户端使用批量 INSERT,降低合并开销)
- 异步模式:将同一个表的 INSERT 缓存在一起,达到一定数量后,才创建新的分片
而在磁盘上,一个分片对应一个目录,其中包含每一列的一个文件。一个分片的行会在 逻辑上 进一步划分为若干组,每组包含 8192 条记录,成为 granule。一个 granule 表示由 ClickHouse 中扫描和索引查询的最小不可再分数据单元。
但是 granule 只是逻辑上的概念,在物理上,磁盘数据是在 chunk(块)级别进行的,chunk 将某一列中多个相邻的 granule 组合在一起。一个块上的 granule 数量不是固定的,因为一个块又大小限制,默认是 1MB,受到该列的数据类型和分布影响。块还会被压缩用来减小大小和 I/O 成本。
为了在存在压缩的情况下仍然能够快速随机访问单个 granule,ClickHouse 会为每一列存储一个映射,用于将每个 granule 的 ID 关联到其所在压缩块在该列文件中的偏移,以及该 granule 在未压缩块中的偏移。
就是一个索引,用于快速查找每个 granule 在存储中的位置
列还可以进一步采用字典编码,比如:LowCardinality(T) 使用整数 ID 替换原始列值,Nullable(T) 则为列 T 添加一个内部位图,用于表示列值是否为 NULL。
最后,表还可以通过分区表达式进行分区(范围分区、哈希分区或轮询分区)。为了实现分区裁剪,ClickHouse 还会为每个分区存储分区表达式的最小值和最大值,用于查询的时候跳过不需要的分区。
Table (users)
│
├── Partition_202401/ ← 分区 (按分区表达式划分)
│ │
│ ├── Part_1/ ← 分片 (不可变, 后台合并)
│ │ │
│ │ │ ── 核心数据文件 ──
│ │ │
│ │ ├── primary.idx ← 稀疏索引 (每个 granule 一个条目)
│ │ ├── id.bin ← 列数据文件 (压缩存储)
│ │ │ ├── [Chunk 0] ──compressed──┐
│ │ │ │ ├── Header │ 压缩算法 / 压缩后大小 / 原始大小
│ │ │ │ ├── Granule 0 (8192行) │
│ │ │ │ ├── Granule 1 (8192行) │ ~1MB
│ │ │ │ └── Granule 2 (8192行) ┘
│ │ │ │
│ │ │ └── [Chunk 1] ──compressed──┐
│ │ │ ├── Header │ 压缩算法 / 压缩后大小 / 原始大小
│ │ │ ├── Granule 3 (8192行) │
│ │ │ └── Granule 4 (8192行) ┘
│ │ │
│ │ ├── id.mrk ← 标记文件 (granule → 定位信息)
│ │ │ ┌────────────┬──────────────┬──────────────────┐
│ │ │ │ Granule ID │ Chunk Offset │ Granule Offset │
│ │ │ │ │ (压缩文件中) │ (解压后块内偏移) │
│ │ │ ├────────────┼──────────────┼──────────────────┤
│ │ │ │ 0 │ 0 │ 0 │
│ │ │ │ 1 │ 0 │ 8192 │
│ │ │ │ 2 │ 0 │ 16384 │
│ │ │ │ 3 │ 1048576 │ 0 │
│ │ │ │ 4 │ 1048576 │ 8192 │
│ │ │ └────────────┴──────────────┴──────────────────┘
│ │ │
│ │ ├── name.bin ← 其他列的数据文件
│ │ ├── name.mrk
│ │ ├── age.bin
│ │ ├── age.mrk
│ │ │
│ │ │ ── 元数据文件 ──
│ │ │
│ │ ├── checksums.txt ← 所有文件的校验和 (数据完整性校验)
│ │ ├── columns.txt ← 该 Part 的列名和类型列表
│ │ ├── count.txt ← 该 Part 的总行数 (COUNT(*) 直接读取)
│ │ ├── partition.dat ← 该 Part 的分区键值
│ │ └── minmax_create_time.idx ← 分区键列的 min/max (分区裁剪用)
│ │
│ └── Part_2/ ← 另一个分片
│ └── ...
│
└── Partition_202402/
└── ...注意:插入行是顺序(主键以及排序键)存储在磁盘上的。
也就是说,后面要讲的写入吞吐、查询裁剪,以及并行化执行,本质上都建立在这套 Part、Column、Granule 的组织方式之上。
1.3 数据写入和合并#
列式数据库的写入路径通常围绕两个目标展开:一是尽可能高吞吐地接收新数据,二是通过后台合并逐步把数据整理成更适合查询的形态。
在前面提到的 MergeTree 模型中,行数据插入后会先形成新的 Part。为了兼顾写入吞吐和查询性能,ClickHouse 一方面允许批量写入和异步聚合写入,另一方面又会依赖后台合并任务持续整理这些 Parts。
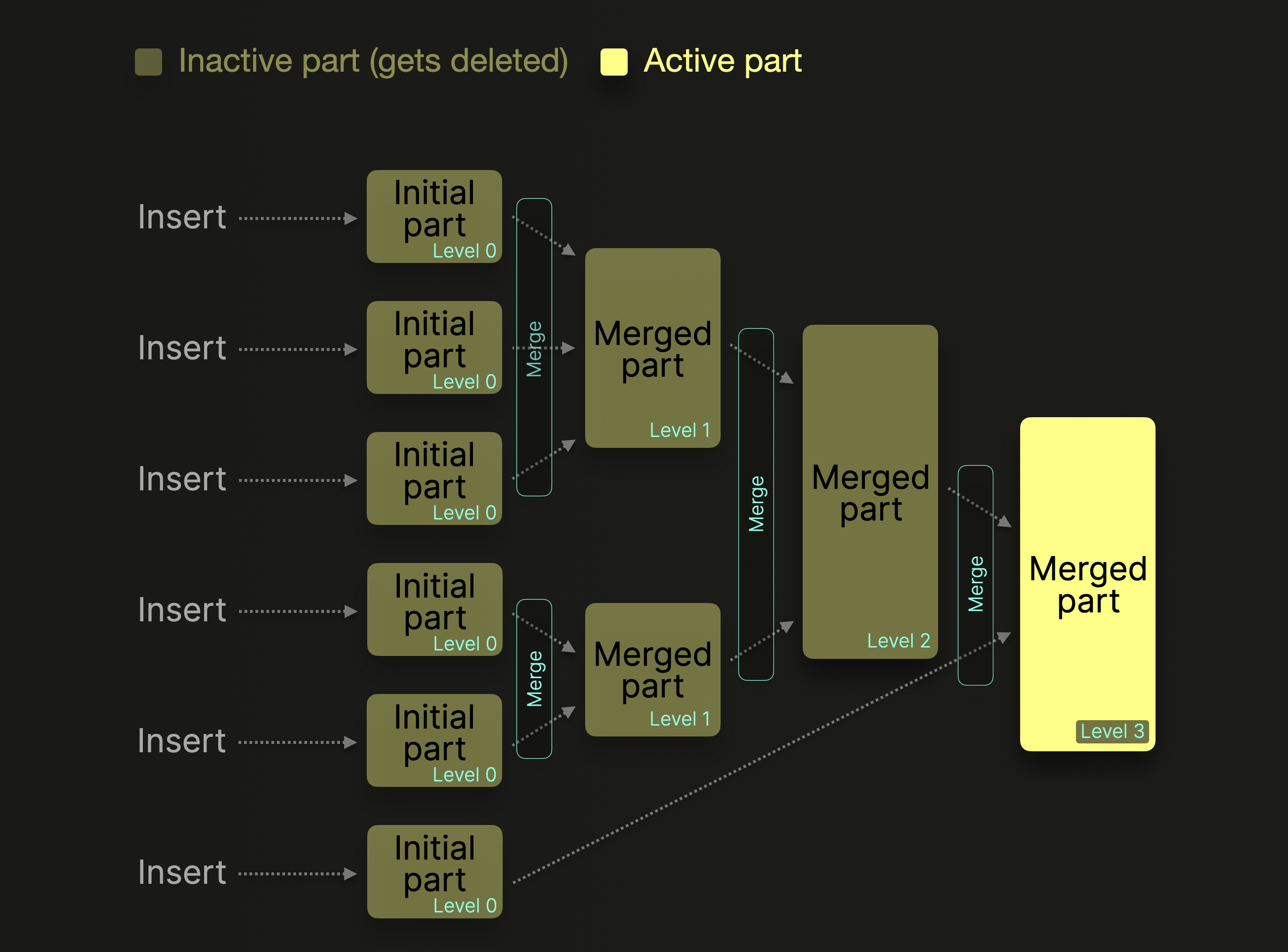
BI 和 Observability 场景要求数据库既能支撑高数据摄取速率,又能通过聚合或数据老化等技术持续减少历史数据量。ClickHouse 提供了不同的合并策略对于已有数据进行持续的增量转换:
- Replacing Merges:通常用作一种合并时更新机制(通常用于更新频繁的场景),或者作为插入时数据去重机制的替代方案。
- Aggregating Merges:将具有相同 primary key 列值的多行折叠为一行聚合结果,非 primary key 列必须是汇总值。
- Time-To-Live (TTL) Merges:为历史数据提供老化机制。可以用于将冷数据移动到成本更低的存储介质中。
在实际的业务场景中,客户端发送数据到服务器时,可能因为各种原因导致无法获取到执行结果(如超时,网络异常等)。这种情况下,客户端无法判断数据是否已经插入到数据库中,在传统的数据库中,往往通过唯一索引来避免重复插入。但是,对于列式数据库来说,维护这样的一个唯一索引带来的开销往往是难以接受的。
因此,ClickHouse 提供了一种更轻量级的替代方案:服务器会维护最近 N 个已经插入 parts 的 hash 值,并忽略哪些 hash 值已经存在的 parts 的重新插入。为了对去重提供更多控制,还允许客户端提供插入数据的 insert token。
这条写入路径也是 ClickHouse 最擅长的“顺风路”:数据尽量以追加和合并的方式被整理。相对地,一旦需求变成直接修改已有数据,代价就会显著上升。
1.4 更新和删除#
MergeTree* 表引擎的设计更适合仅追加(append-only)的工作负载,但某些场景下仍需要偶尔修改已有数据。
更新时,ClickHouse 会就地重写表中的所有 parts。如果要避免删除整表或者更新列时,表或者列的大小在短时间内翻倍,这个操作就无法提供原子性(如果要提供原子性,需要一次性生成新副本,修改完成后再替换旧的 part)。不提供原子性,意味着并行执行的 SELECT 可能同时读取到已修改和未修改的 parts。这样也可以减少修改带来的开销。
删除时,依然需要较大的开销,因为如果要删除特定行,则需要对表的所有列进行删除。作为替代方案,ClickHouse 提供了轻量级删除(Lightweight Delete),即额外维护一个位图列,用于标记某一行是否被删除。在 SELECT 查询时,再针对该位图列进行过滤。
轻量级删除可以降低删除带来的开销,但是会降低查询性能。
1.5 查询与裁剪#
前面介绍存储结构、append-only Part 和排序键,并不是为了把磁盘格式讲得更完整,而是因为这些设计最终都会体现在查询阶段:它们共同服务的目标,是让分析查询尽可能减少无效扫描。
就算是列式存储,可以减少 I/O,但是面对单次查询就要扫描 PB 级别的数据时,速度和成本也难以接受,因此数据库往往还需要进一步减少扫描的数据量,这就是数据裁剪的目的。
在 ClickHouse 中数据裁剪通过以下方式实现:
-
主键索引:(稀疏索引) 通过为表定义主键索引,来决定每个 Partition 中行的排序顺序,该索引是局部聚簇。另外分区内还会存储每个 Granule 中的首个主键列值到 Granule ID 的映射。这样查询时,如果是根据主键列查询,那么可以二分查找主键索引来快速定位。
-
表投影: 即包含相同行,但是按照不同的主键排序的表。但是很显然,这样会增加 insert、merge 和存储开销。
-
跳过索引: 这是一种比投影更轻量的方案。它旨在索引数据块(多个连续 Granule 的层级)存储少量元数据,从而避免扫描无关行。ClickHouse 中支持的跳过索引有:
- MinMax:为每个索引数据块存储索引表达式的最小值和最大值。
- Set:存储每个索引数据块中可配置数量的唯一值。
- BloomFilter:针对行、token 或者 n-gram 值进行构建。
一条分析查询在 ClickHouse 中通常不是像 OLTP 数据库那样,先命中某个索引,再迅速精确定位到某一行并返回结果;更常见的方式是逐层减少扫描范围。
- 查询会先根据分区条件做分区裁剪,再根据主键稀疏索引缩小到候选 granule;
- 如果还定义了跳过索引,那么可以继续排除不可能命中的数据块。
- 等这些裁剪都完成之后,系统才真正去读取涉及的列,并执行过滤、聚合等算子。
因此,ClickHouse 的优化重点并不是“精确命中单行”,而是尽可能减少无效扫描的分区、块和列。不同查询模式在这种设计下的收益也不一样。
- 对于点查来说,ClickHouse 并不占优势,因为最小扫描单位仍然是 granule,很难像 B+ 树那样精准命中单行;
- 对于范围查询来说,如果过滤条件和排序键方向一致,稀疏索引通常能较有效地缩小候选范围;
- 而对于聚合查询来说,列式存储的优势会最明显,因为查询往往只需要读取少量列,并且天然适合向量化执行和批量计算。
当存储结构、写入路径和查询裁剪都确定之后,剩下的问题就变成:这套系统还能如何扩展、并为了吞吐接受哪些系统级代价。
1.6 数据复制#
ClickHouse 基于 Raft 协议提供分布式且具备容错的协调层。当各节点执行本地的 insert、merge、mutation 和 DDL 语句时,复制日志会在所有其他节点上异步回放。这里不关注列式数据库的分布式特性,因此也不展开。
1.7 ACID 特性#
为最大化并发读写操作的性能,ClickHouse 尽可能避免使用锁。查询在开始时会基于所有相关表中全部 parts 的一个快照来执行。这样可以保证在执行期间,由并行 INSERT 或合并操作新插入的 parts 不会参与本次查询执行。为防止 parts 被同时修改或删除,在查询执行期间,会增加这些被处理 parts 的 引用计数。
因此,ClickHouse 从严格意义上来说并不满足 ACID,只有 SELECT 和 INSERT 并行时,能做到互不影响(INSERT 会新建一个 part,而 SELECT 会对 parts 产生一个快照)。
这样的取舍在 OLAP 场景下是完全可以接受的,放弃原子性可以换来更高的读写性能。
1.8 并行化查询#
前面介绍过 ClickHouse 中采用了多层级存储结构,得益于这样的设计,查询时可以分三个层级对查询进行并行化,这三个层级分别是:表分片(Table Shard)、数据块(Data Chunks)和数据元素(Data Elements)。
表分片,这里是指分布式架构中,将分布式表根据分片键将数据分配到不同的 Shard (位于不同的节点或者集群)上,每个 Shard 本质上都是一个独立的表。
这一点和传统数据库的分库分表相同。
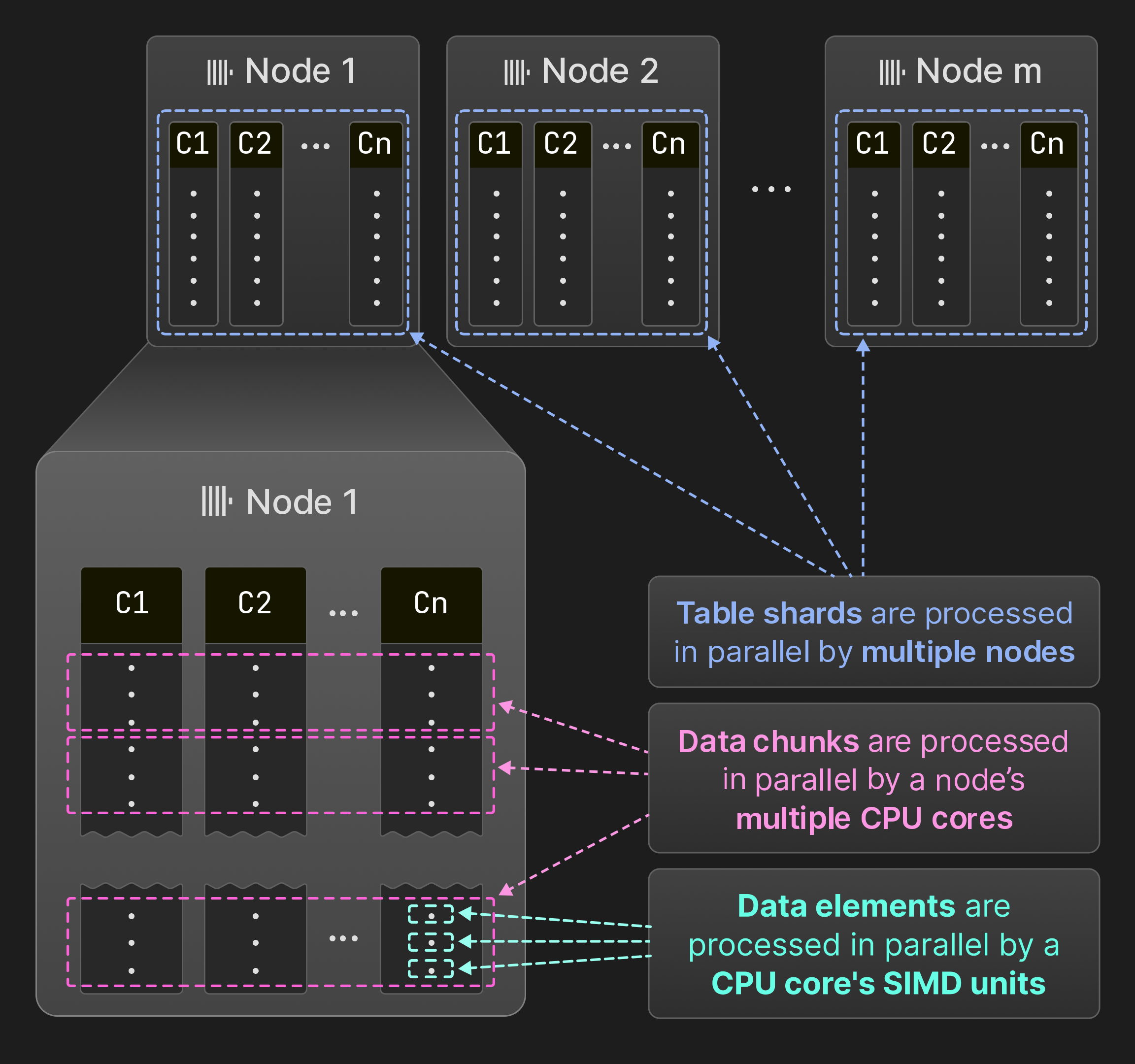
这里提到的 SIMD(Single Instruction Multiple Data)是一种并行计算技术,可以提升算术运算、过滤和聚合的性能。比如前面提到的删除位图,就可以利用 SIMD 与命中行的位图进行位运算,用一条 CPU 指令即可完成多行数据的过滤。
至于多核和多节点并行,涉及比较多的细节(Physical Plan、Repartition、Aggregation、Merge 等),这里也不展开了。
小结#
到这里,前面这些看起来分散的主题,其实都可以重新压回同一张设计图:存储结构决定了写入路径、修改代价、查询裁剪方式,以及一致性和并行化的边界。
ClickHouse 的存储是一个多级结构,每一级都有明确的职责:
Table → Partition → Part → Column File (.bin) → Compressed Chunk → Granule- Partition(分区):按业务维度(通常是时间)划分数据,配合
minmax_*.idx实现分区裁剪,查询时整块跳过无关分区。 - Part(分片):数据写入的基本单位,不可变,后台异步合并。不可变性让并发读写无需加锁(SELECT 基于 parts 快照执行),代价是更新和删除开销大。
- Column File(列文件):每列独立存储,查询时只读取涉及的列;同类型数据连续排列,天然适合压缩编码。
- Compressed Chunk(压缩块):物理 I/O 的最小单位(~1MB),包含 Header 和多个 Granule 的压缩数据。通过
.mrk标记文件实现 Granule 级别的随机访问而无需解压整个列文件。 - Granule(粒度):逻辑上的最小扫描单元(8192行),稀疏索引和跳过索引都以 Granule 为粒度工作。粒度越小定位越精确,但索引开销越大。
换句话说,1.2 解释了这张结构图本身,1.3 和 1.4 解释了它为何擅长追加写入却不擅长原地修改,1.5 解释了它为何能减少查询扫描量,而 1.6 到 1.8 则补上了这套设计在复制、一致性和并行执行上的系统级边界。
设计上的核心取舍:
| 选择 | 获得 | 牺牲 |
|---|---|---|
| 列式存储 | 高压缩率、列裁剪、向量化计算 | 点查不友好 |
| 不可变 Part(append-only) | 无锁并发、简化一致性 | 更新/删除代价高 |
| 稀疏索引(非 B+ 树) | 索引体积小可以常驻内存,维护成本低 | 点查不友好,最小扫描单位是 Granule |
| 放弃严格 ACID | 更高的读写吞吐 | 并发修改时无事务隔离 |
| Part hash 去重(非唯一索引) | 写入路径轻量 | 只能去重整个 Part,非行级去重 |
| 按分区组织数据 | 分区裁剪、冷热数据管理更自然 | 分区过细会导致 Part 过多,过粗又会削弱裁剪效果 |
| 较大的 Granule / Chunk | 索引更稀疏、元数据更少、顺序 I/O 更友好 | 过滤不够精确,可能为了少量命中数据多扫一个 granule |
| 后台异步合并(merge) | 写入路径轻、吞吐高、读写更容易并发 | 会带来写放大,且查询性能会受 merge 进度影响 |
2. 手搓一个最小列式数据库#
前面已经拆完了 ClickHouse 的核心设计,但真实的生产级系统太复杂,不可能在一篇文章里完整复刻。好在如果只保留几个最关键的机制:分区、Part、列文件、稀疏索引、列裁剪,其实已经足够拼出一个最小可用的列式数据库骨架。下面我们尝试站在实现者的角度,把这些设计重新串起来。
2.1 先定义 MVP 的能力边界#
在动手之前,先主动砍掉一大批能力,把目标收敛到一个最小闭环。
我们只支持:
- 单机
- 单表
- append-only 写入
- 按时间字段分区
- 分区内按一个排序键排序
- 每个 granule 维护一条稀疏索引
- 支持 filter +
sum/count这类简单聚合查询
我们明确不支持:
- update
- delete
- join
- 事务
- 压缩
- 分布式执行
这样做的目的是让核心结构尽量清晰:只关注一批行是如何写入成列式结构的,以及一条查询是如何一步步减少扫描量的。
2.2 核心数据结构#
如果把前面介绍过的概念压缩成最小模型,那么核心结构大概如下:
Table
└── Partitions[partition_key]
└── Parts[]
├── ColumnFiles[column_name]
└── PrimaryIndex[]其中每一层的职责分别是:
Table:保存表的 schema、分区键、排序键,以及所有分区的入口。Partition:按照分区键组织数据,例如按天或者按月保存同一时间范围内的多个 Part。Part:一次批量写入形成的不可变数据块,内部已经按排序键排好序。ColumnFile:Part 中每一列独立存储的数据文件。Chunk:ColumnFile 的内部结构,包含 Header 和多个 Granule 的数据,压缩单元。Granule:逻辑上的最小扫描单元(8192行),primary_index和跳过索引都以 Granule 为粒度工作。

这里最关键的一点是:Part 内部按排序键有序、列独立存储、granule 级别有 primary_index。只要这三点成立,后面的查询裁剪就有了基础。
2.3 写入路径伪代码#
接下来考虑一批行写进来之后,会发生什么。

使用伪代码描述如下:
def insert(rows):
grouped = group_by(rows, partition_key)
for partition_value, partition_rows in grouped:
sorted_rows = sort_by(partition_rows, sort_key)
granules = split_into_granules(sorted_rows, granule_size=8192)
part = Part(schema=schema, sort_key=sort_key, granules=granules)
partitions[partition_value].add_part(part)
class Part:
def __init__(self, schema, sort_key, granules):
self.schema = schema
self.sort_key = sort_key
self.granules = granules
self.primary_index = self._build_primary_index()
self.column_files = self._build_column_files()
def _build_primary_index(self):
index = []
for granule_id, granule in enumerate(self.granules):
index.append({
"first_sort_key": granule.rows[0][self.sort_key],
"granule_id": granule_id,
})
return index
def _build_column_files(self):
column_files = {}
for column in self.schema:
column_files[column] = []
for granule in self.granules:
column_files[column].append(extract_column(granule.rows, column))
return column_files这段流程看起来很朴素,但已经包含了列式数据库最关键的几个动作:
- 按分区键分桶:让后续查询可以先裁剪整个分区。
- 按排序键排序:让相邻数据在逻辑上更有局部性,便于索引裁剪。
- 切成 granule:把最小扫描单位控制在一个比行更粗,但又足够细的粒度上。
- 按列写入:支持列裁剪,同时对聚合算子更友好。
- 构造
primary_index:记录每个 granule 的首个排序键值,用于查询时快速排除不可能命中的 granule。
也就是说,一批行数据在写入完成后,不再是“很多行记录”,而是变成了:按分区组织的多个 Part,每个 Part 内部按列存储,并额外带有 granule 级别的 primary_index。
2.4 查询路径伪代码#
再来看一条带过滤和聚合的查询是怎么执行的。
def query(partition_predicate, sort_key_predicate, other_predicates, aggregate_column):
result = 0
candidate_partitions = prune_partitions(partitions, partition_predicate)
for partition in candidate_partitions:
for part in partition.parts:
candidate_granules = prune_granules(part.primary_index, sort_key_predicate)
predicate_columns = read_predicate_columns(part, candidate_granules, [
sort_key_predicate.column,
*columns_of(other_predicates),
])
for granule_id in candidate_granules:
matched_row_ids = filter_granule(
predicate_columns,
granule_id,
sort_key_predicate,
other_predicates,
)
values = read_column_values(part, aggregate_column, granule_id, matched_row_ids)
result += aggregate(values)
return result
这条伪代码更接近 sum 这一类需要读取聚合列的执行路径;如果是 count,只需要统计 matched_row_ids,不必读取聚合列。
这条路径里,真正重要的不是代码细节,而是扫描量如何被一层层削减:
- 先裁剪分区:不在时间范围内的分区整块跳过。
- 再裁剪 granule:通过
primary_index只保留可能命中的 granule。 - 读取谓词列并筛出命中位置:只读取过滤条件涉及的列,在 granule 内找出真正命中的行位置。
- 最后读取聚合列并计算:只对命中的位置读取目标列值,再执行聚合。
换句话说,primary_index 的作用是先缩小候选 granule 的范围,而真正的过滤发生在读取谓词列之后,真正的值读取发生在聚合列阶段。
这里的“值读取”特指最终聚合目标列的值读取,不包括前面为了过滤而读取的谓词列。
这其实就是前面反复提到的三个关键词:先缩小分区 / Part 扫描范围、再减少 Granule、最后减少列 I/O。
2.5 用一个查询例子串起来#
假设现在有这样一条查询:
SELECT sum(amount)
FROM orders
WHERE dt BETWEEN '2026-03-01' AND '2026-03-31'
AND user_id = 1001它的执行过程可以理解为:
第一步,数据库先根据 dt 做分区裁剪。假设表是按月分区,那么 3 月之外的分区可以直接跳过,连对应的 Part 都不需要打开。
第二步,在命中的 3 月分区里,再查看每个 Part 的 primary_index。只有当 Part 内部的数据按 user_id 排序,或者 user_id 是排序键的前导列时,数据库才能先圈定哪些 granule 可能包含 user_id = 1001;但这一步只能缩小候选 granule,不能像 B+ 树那样直接定位到具体行。
第三步,真正读取数据时,也不需要把整行都读出来,只需要先读取过滤条件涉及的列。这里通常先读取 user_id,在候选 granule 内筛出真正命中的行位置;如果 dt 已经在分区裁剪阶段处理掉,甚至连 dt 列本身都不需要读取。
第四步,在命中的位置确定之后,再去读取 amount 列对应的值,并把这些值逐步累加起来。
走完这个过程就会发现,列式数据库真正高效的地方,并不只是“按列存”这四个字,而是它围绕“减少扫描量”形成了一整套层层递进的组织方式:
- 分区负责减少需要扫描的 Part
primary_index负责减少需要扫描的 Granule- 谓词列负责筛出真正命中的位置
- 聚合列负责在命中的位置上读取值并计算结果
这也是为什么说,列式数据库的核心不只是换了一种存储格式,而是围绕分析查询重新组织了整条数据路径。