
本文主要解决在服务重构过程中如何保证新旧服务行为一致性的问题。
场景描述 #
现有一个 python 开发的 gRPC 微服务提供了一些 数据查询 接口 供 上层应用使用,随着业务流量的增加运维这个服务的成本也逐渐增加,为了降低运维成本和提高性能 (木有擅长 python 高性能的开发),因此选择了使用 go 语言对这个服务进行重写。在开发完成之后,需要对新服务的 gRPC 接口进行验证。
这种场景对测试开发人员来说,实在是太熟悉了吧?典型的 重放验证,马上能想到的验证手段就是:
- 如果有存量的单元测试,那么直接重新跑一遍单元测试就能快速的完成验证。
- 没有单元测试的情况,那么可以将新服务部署起来,通过流量复制的方式将旧服务的流量复制到新服务上,然后对比两个服务的返回结果是否一致。
flowchart LR
%% 定义布局方向和间距
subgraph s1["方案一: 单元测试验证"]
direction TB
UT[单元测试] -->|执行| NS1[新服务]
end
subgraph s2["方案二: 流量复制验证"]
direction TB
C[客户端] -->|请求| OS[旧服务]
OS -->|响应| C
OS -->|复制流量| NS2[新服务]
NS2 -->|对比响应| OS
end
%% 设置布局方向和对齐方式
s1 ~~~ s2
但是很遗憾 😭,并没有成熟的单元测试;测试人员也都是人肉测试,对于内部服务的接口验证帮助不大,因此这里采用第二种方式进行验证。
服务均采用 Kubernetes 部署。
方案介绍 #
HTTP 流量的复制重放工具就很多很成熟了,而且往往在 网关/代理 一侧就能实现流量复制甚至对比。
| 工具 | 分类 | 文档链接 |
|---|---|---|
| Nginx mirror | 网关/代理 | https://nginx.org/en/docs/http/ngx_http_mirror_module.html |
| APISIX | 网关/代理 | https://apisix.apache.org/docs/apisix/plugins/proxy-mirror/ |
| Istio: Virtual Service mirror | Service Mesh | https://istio.io/latest/docs/tasks/traffic-management/mirroring/ |
| GoReplay | 流量镜像 | https://github.com/buger/goreplay |
| tcpcopy | 流量镜像 | https://github.com/session-replay-tools/tcpcopy |
tcpcopy 相比于其他工具方案,虽然不能直接使用,但是其作用于 TCP 传输层,功能会更丰富。相比之下,gRPC 流量复制工具就没有那么成熟了。
由于这里是一个 Kubernetes gRPC 微服务,可以想到的就是使用 sidecar 容器的方式来实现流量镜像,并记录到本地文件中,然后通过对比脚本来对比新旧服务的响应内容。
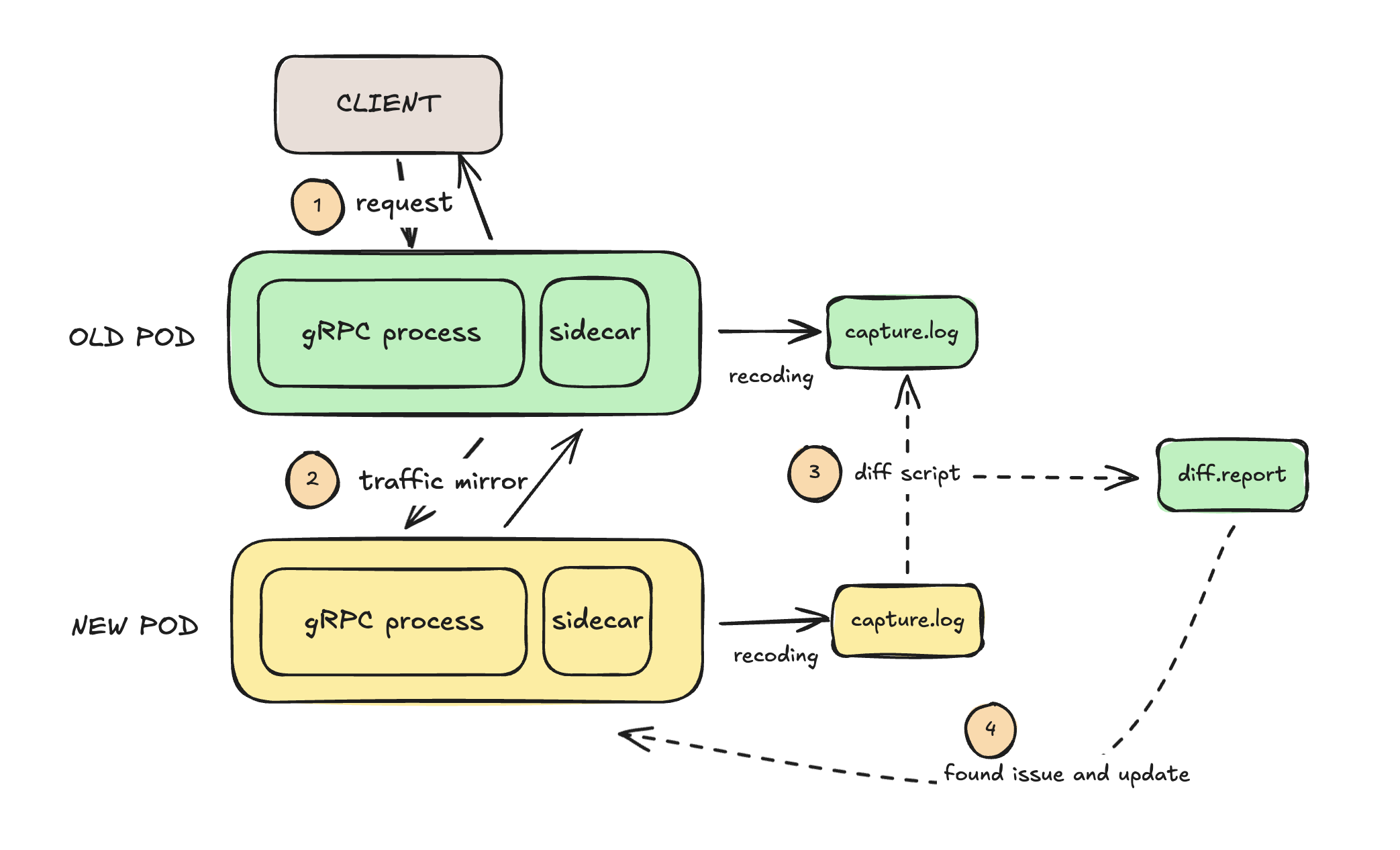
Kubernetes 中的 sidecar #
Kubenetes 中的 sidecar 是指在应用容器之外,部署一个独立的容器,用于处理应用容器的请求和响应。sidecar 容器和应用容器共享同一个网络命名空间,因此可以通过 localhost 来进行通信。
因此不管是使用 Istio 还是 grpcreplay,都需要在应用容器之外部署一个 sidecar 容器。只不过两个容器的作用原理不相同,grpcreplay 一个是通过嗅探网络协议栈上的 gRPC 流量,将这部分数据报文解析再使用;而 Istio 则是接管了应用容器的请求和响应,然后将流量复制到新的服务上。
grpcreplay 简介 #
grpcreplay 是一款开源的 gRPC 流量解析和重放工具,它类似于 goreplay 都是通过抓包实现流量的复制,而不是代理的方式。另外它还支持多种输入输出,包括文件、网卡、消息队列、标准输入输出等。当然也有一些限制:
- 目前支持到 h2c 暂不支持 h2
- 序列化器支持 protobuf
- 不支持 Streaming
h2c 指的是 HTTP/2 over TCP,h2 指的是 HTTP/2 over TLS/SSL。
grpcr help message
$ grpcreplay -h
______ ____ ____ ______ ____
/ ____// __ \ / __ \ / ____// __ \
/ / __ / /_/ // /_/ // / / /_/ /
/ /_/ // _, _// ____// /___ / _, _/
\____//_/ |_|/_/ \____//_/ |_|
Usage of grpcreplay:
-codec string
(default "simple")
-exit-after duration
exit after specified duration
-include-filter-method-match string
filter requests when the method matches the specified regular expression
-input-file-directory value
grpcr --input-file-directory="/tmp/mycapture" --output-grpc="grpc://xx.xx.xx.xx:35001“ (default [])
-input-file-read-depth int
(default 100)
-input-file-replay-speed float
(default 1)
-input-raw value
Capture traffic from given port (use RAW sockets and require *sudo* access):
# Capture traffic from 80 port
grpcr --input-raw="0.0.0.0:80" --output-grpc="grpc://xx.xx.xx.xx:35001"
(default [])
-input-rocketmq-access-key string
-input-rocketmq-group-name string
(default "fakeGroupName")
-input-rocketmq-name-server value
grpcr --input-rocketmq-name-server="192.168.2.100:9876" --output-grpc="grpc://xx.xx.xx.xx:35001" (default [])
-input-rocketmq-secret-key string
-input-rocketmq-topic string
(default "test")
-output-file-directory value
Write incoming requests to file:
grpcr --input-raw="0.0.0.0:80" --output-file-directory="/tmp/mycapture" (default [])
-output-file-max-age int
MaxAge is the maximum number of days to retain old log files
based on the timestamp encoded in their filename (default 30)
-output-file-max-backups int
MaxBackups is the maximum number of old log files to retain. (default 10)
-output-file-max-size int
MaxSize is the maximum size in megabytes of the log file before it gets rotated. (default 500)
-output-grpc value
Forwards incoming requests to given grpc address.
# Redirect all incoming requests to xxx.com address
grpcr --input-raw="0.0.0.0:80" --output-grpc="grpc://xx.xx.xx.xx:35001") (default [])
-output-grpc-worker-number int
multiple workers call services concurrently (default 5)
-output-rocketmq-access-key string
-output-rocketmq-name-server value
grpcr --input-raw="0.0.0.0:80" --output-rocketmq-name-server="192.168.2.100:9876" (default [])
-output-rocketmq-secret-key string
-output-rocketmq-topic string
(default "test")
-output-stdout
Just prints data to console
-rate-limit-qps int
the capture rate per second limit for Query (default -1)
-record-response
record response
-version
print version
实践1: grpcreplay sidecar #
想要把 grpcreplay 想要作为 sidecar 容器部署在 Kubernetes 中,这里需要做的工作有:
- grpcreplay 镜像打包并推送到镜像仓库
- 添加 PVC 以存储 grpcreplay 的流量数据
- 修改新旧服务的 Deployment 以配置 sidecar 容器。
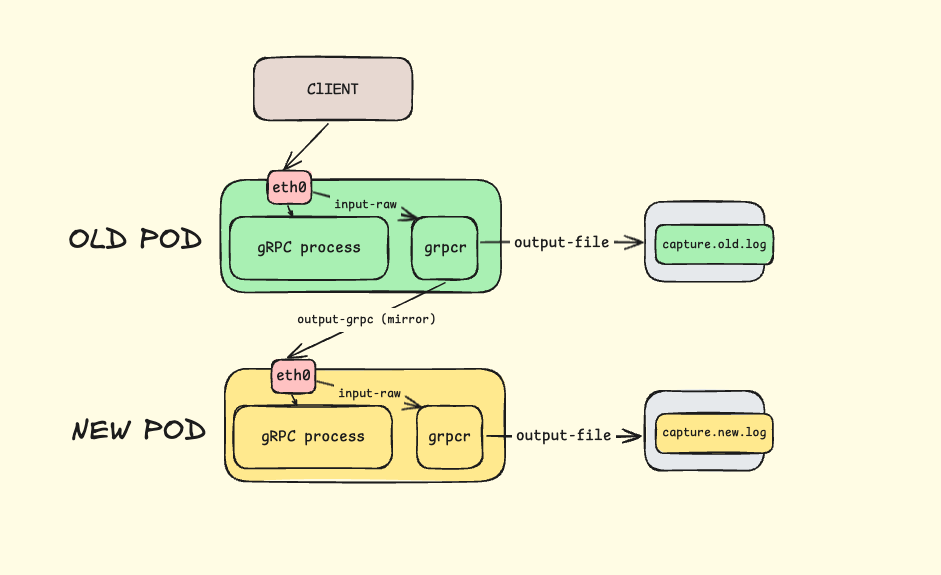
架构设计 #
图以蔽之:
镜像打包 #
提前将 grpcreplay 源码下载到本地,然后编写 Dockerfile 进行构建。
FROM golang:1.23.6 AS builder
WORKDIR /go/src/github.com/vearne/grpcreplay/
COPY . /go/src/github.com/vearne/grpcreplay/
# 安装依赖
RUN apt-get update && apt-get install -y libpcap-dev
RUN go get
# 构建应用
RUN CGO_ENABLED=1 go build -ldflags "-s -w" -o grpcr
# 使用多阶段构建减小镜像大小
FROM debian:bookworm-slim
# 安装运行时依赖
RUN apt-get update && \
apt-get install -y libpcap0.8 && \
apt-get clean && \
rm -rf /var/lib/apt/lists/*
WORKDIR /app
# 从构建阶段复制二进制文件
COPY --from=builder /go/src/github.com/vearne/grpcreplay/grpcr /app/
# 设置容器入口点
ENTRYPOINT ["/app/grpcr"]
# 构建镜像
podman build --platform linux/amd64 --rm -t grpcr -f Dockerfile .
# 修改镜像标签
podman tag grpcr yeqown/grpcr:v0.2.6
# 推送到 hub.docker.com 镜像仓库 https://hub.docker.com/repository/docker/yeqown/grpcr
podman push yeqown/grpcr:v0.2.6
添加 PVC #
这里仅供参考,也不是必要的步骤,只要能给 POD 挂载一个 PV 即可。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: grpc-capture-pvc
spec
accessModes:
- ReadWriteMany # 多个Pod需要同时访问
resources:
requests:
storage: 10Gi
storageClassName: YOUR_STORAGE_CLASS_NAME # 替换为你的存储类名称
配置 Sidecar: grpcreplay #
配置新旧服务的 Deployment 文件以配置 sidecar 容器。同样的这里以实际情况为准
旧服务:
apiVersion: apps/v1
kind: Deployment
metadata:
name: old-grpc
labels:
app: old-grpc
spec:
replicas: 1
selector:
matchLabels:
app: old-grpc
template:
metadata:
labels:
app: old-grpc
spec:
containers:
- name: old-grpc
image: your-registry/old-grpc:latest
ports:
- containerPort: 50051 # gRPC服务端口
+ # grpcreplay sidecar容器
+ - name: grpcreplay
+ image: docker.io/yeqown/grpcr:v0.2.6
+ securityContext:
+ capabilities:
+ add: ["NET_ADMIN", "NET_RAW"] # 需要这些权限来捕获网络流量
+ args:
+ - "--input-raw=0.0.0.0:50051"
+ - "--output-grpc=grpc://new-grpc:50051"
+ - "--output-file-directory=/capture/server"
+ - "--record-response"
+ - "--codec=json"
+ volumeMounts:
+ - name: capture-volume
+ mountPath: /capture/server
+ volumes:
+ - name: capture-volume
+ persistentVolumeClaim:
+ claimName: grpc-capture-pvc
新服务:
apiVersion: apps/v1
kind: Deployment
metadata:
name: new-grpc
labels:
app: new-grpc
spec:
replicas: 1
selector:
matchLabels:
app: new-grpc
template:
metadata:
labels:
app: new-grpc
spec:
containers:
- name: new-grpc
image: your-registry/new-grpc:latest
ports:
- containerPort: 50051 # gRPC服务端口
+ # grpcreplay sidecar容器(可选,用于记录请求和响应)
+ - name: grpcreplay
+ image: docker.io/yeqown/grpcr:v0.2.6
+ securityContext:
+ capabilities:
+ add: ["NET_ADMIN", "NET_RAW"]
+ args:
+ - "--input-raw=0.0.0.0:50051"
+ - "--output-stdout"
+ - "--output-file-directory=/capture/mirror"
+ - "--record-response"
+ - "--codec=json"
+ volumeMounts:
+ - name: capture-volume
+ mountPath: /capture/mirror
+
+ volumes:
+ - name: capture-volume
+ persistentVolumeClaim:
+ claimName: grpc-capture-pvc
服务启动后,会在 /capture/server 和 /capture/mirror 目录下生成 grpcreplay 的流量数据。
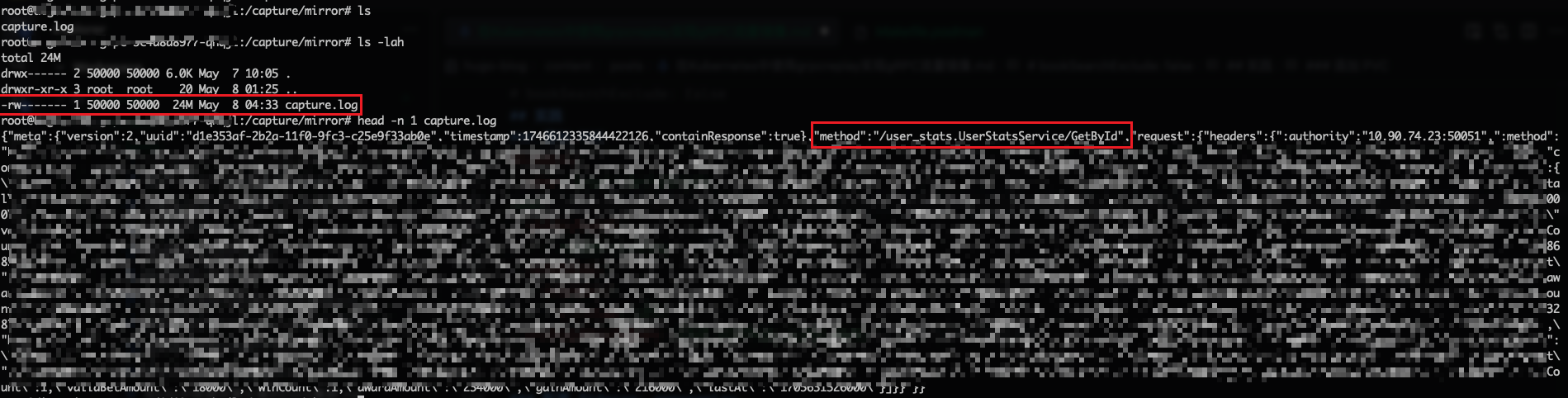
踩坑记录 #
使用 grpcreplay 作为 sidecar 容器部署在 Kubernetes 中后,经过一段时间后,发现记录的文件会出现如下的情况:
- 单行数据不完整,JSON 无法解析
- Response 记录和方法不匹配,如:请求 Method1 但是记录的 Response 确实 gRPC 健康检查的响应
- 某些记录 Request 为空,实际上该请求并不为空。
导致对比无法进行,会出现误判的情况。
大概率是 grpcreplay 本身采集写入的问题,这里再没有进一步深入追查。
实践2: Istio VirtualService mirror #
Istio 是一个非常成熟的 Service Mesh 解决方案,它可以在不修改应用代码的情况下,对 gRPC 流量进行镜像和重放。只需要为服务配置好 VirtualService mirror 规则即可。
| 字段 | 路径层级 | 描述 |
|---|---|---|
| mirror | spec.http[].mirror |
指定要镜像的目标服务。 |
| mirrorPercentage | spec.http[].mirrorPercentage |
指定要镜像的流量百分比。 |
复制流量之后,这个方案还需要获取 gRPC 服务的响应内容,记录到本地文件中,然后通过对比脚本来对比新旧服务的响应内容。这里可以考虑实现 Istio 的插件去记录,也可以选择在服务中添加 gRPC 拦截器来实现记录。
配置源服务 VirtualService #
这里为 old-grpc 服务配置 VirtualService。
apiVersion: networking.istio.io/v1beta1
kind: Gateway
metadata:
name: istio-gateway
namespace: xxx
spec:
selector:
istio: ingressgateway
servers:
- hosts:
- old-grpc.xxx.com
port:
name: grpc
number: 443
protocol: GRPC
---
apiVersion: networking.istio.io/v1
kind: VirtualService
metadata:
name: old-grpc
spec:
hosts:
- old-grpc.default.svc.cluster.local
- old-grpc.xxx.com
gateways:
- xxx/istio-gateway
http:
- route:
- destination:
host: old-grpc.default.svc.cluster.local
port:
number: 50051
weight: 100
mirror:
host: new-grpc.default.svc.cluster.local
mirrorPercentage:
value: 100
踩坑记录 #
‼️ 这里在实践过程中遇到的问题是:使用了 AWS 的 ALB 作为 Ingress Load Balancer,old-grpc 原始暴露了 old-grpc.xxx.com 的一个对外服务的域名,在将该 ingress 的 backend 切换到 istio-ingressgateway 之后,请求异常 (请求响应状态码: UNIMPLEMENTED)。

从上图可以发现,ingressgateway 未能正确的将请求转发到对应的后端服务(Service = Unkonwn) 所有的请求全都失败了,这里的问题是:
- 原本 ALB 处的配置是按照 HTTP(s) 配置的,转发到了 ingressgateway 的 80 端口,而 ingressgateway 的 80 端口配置为处理 HTTP 流量。
- istio ingressgateway 可能存在无法自动识别流量的情况,需要显示的配置 gRPC 协议。
第一个问题的解决方案是:将 ingress 转发端口从 80 改为 443。同时需要注意 AWS 转发过来的流量也需要在 ingress 中添加注解 alb.ingress.kubernetes.io/backend-protocol-version: "GRPC"
第二个问题的解决方案是:service 显式的配置为 gRPC 协议。port name 改为:protocol[-suffix] 格式,或者在 kubernetes 1.18+ 版本中直接使用 appProtocol 字段。如下:
apiVersion: v1
kind: Service
metadata:
name: old-grpc
namespace: xxx
spec:
selector:
app: old-grpc
ports:
- name: grpc-xxx # 显示的配置为 gRPC 协议
appProtocol: grpc # 显式的配置为 gRPC 协议,这个配置的优先级更高
port: 50051
protocol: TCP
编写 gPRC interceptor #
各个语言要实现 gRPC 拦截器的方式都不尽相同,但都大差不差,这里以 python 语言为例:
PS: 为啥用 python 举例?对我来说,它是真抽象~
from grpc_interceptor import ServerInterceptor
class RecordReqRespInterceptor(ServerInterceptor):
"""
Interceptor to record request and response information.
Usage:
server = grpc.server(
ThreadPoolExecutor(max_workers=5),
interceptors=[RecordReqRespInterceptor(store_directory)])
"""
fd = None
store_directory = None # /capture/server/capture.log
_lock = threading.Lock() # 添加线程锁
def __init__(self, store_directory=None):
if not store_directory:
__LOGGER__.warning(
"Warning: store_directory is not specified, request and response information will not be recorded.")
return
filename = store_directory + "capture.log"
try:
self.store_directory = filename
self.fd = open(filename, 'a')
except Exception as e:
__LOGGER__.error(f"Failed to open file {store_directory}: {e}")
def record(self, call_detail: CallDetails, error: str = None):
if self.fd is None or self.store_directory is None:
return
# 从handler_call_details中提取基本信息
method = call_detail.method
if method in [
"/grpc.health.v1.Health/Check",
"/grpc.reflection.v1.ServerReflection/ServerReflectionInfo",
"/grpc.reflection.v1alpha.ServerReflection/ServerReflectionInfo",
]:
return
metadata = dict(call_detail.invocation_metadata)
timestamp_nano = time.time_ns()
timestamp_seconds = int(timestamp_nano / 1000000000)
req_body = json.dumps(MessageToDict(call_detail.request), separators=(',', ':'))
resp_body = json.dumps(MessageToDict(call_detail.response), separators=(',', ':'))
# 构建记录
record = {
"method": method,
"request": {
"headers": metadata,
"body": req_body,
},
"response": {
"headers": {
"failed": error is not None,
"error": error if error else "",
},
"body": resp_body,
}
}
try:
with self._lock: # 使用锁保证写入原子性
self.fd.write(json.dumps(record) + '\n')
self.fd.flush()
except Exception as e:
__LOGGER__.error(f"Failed to write to file {self.store_directory}: {e}")
# 实现 ServerInterceptor 抽象方法
def intercept(
self,
method: Callable,
request_or_iterator: Any,
context: grpc.ServicerContext,
method_name: str,
):
response = method(request_or_iterator, context)
self.record(CallDetails(method_name, context, request_or_iterator, response))
return response
对比脚本 #
capture.log 中的保存每一条记录 JSON 结构如下:
{
"method": "/pbpkg.Service/Method",
"request": {
"headers": {
":authority": "10.90.74.23:50051",
":method": "POST",
":path": "/pbpkg.Service/Method",
":scheme": "http",
"content-type": "application/grpc",
"grpc-accept-encoding": "gzip",
"te": "trailers",
"user-agent": "grpc-go/1.61.0"
},
"body": "<ignored data string>"
},
"response": {
"headers": {
":status": "200",
"content-type": "application/grpc",
"grpc-message": "",
"grpc-status": "0"
},
"body": "<ignored data string>"
}
}
JSON 中已经详细的记录了请求和响应的内容,注意一定需要在请求头中携带一条唯一表示,比如 trace_id 或者 request_id 方便将源服务器和 镜像服务器的请求响应串联起来。脚本的对比逻辑伪代码如下:
def parse_capture_log(log_file) -> Record:
"""
解析 grpcreplay 生成的 capture.log 文件,返回一个 Record 对象
"""
records = {}
with open(log_file, "r") as f:
for line in f:
record = Record.parse_raw(line)
records[record.uuid] = record
def main():
source_records = parse_capture_log("capture.source.log")
mirror_records = parse_capture_log("capture.mirror.log")
for source_record in source_records:
mirror_record = mirror_records.get(source_record.uuid)
diff = source_record.diff(mirror_record)
if diff:
# 展示差异
print(f"Request {source_record.uuid} is different:")
print(diff)
# 统计对比结果:总共有多少条记录,有多少条记录不同;多少个 method 不同;method 各有多少条记录不同;
# 统计 method 不同的原因:请求头不同、请求体不同、响应头不同、响应体不同;
print_summary()
这里需要注意的是原始服务器和镜像服务器保存的JSON结构可能存在差异, 比如:
- 字段的序列化顺序不同,如:
{"a": 1, "b": 2}和{"b": 2, "a": 1} - 对于空值的(序列化)处理不同,如:
{"a": 1, b: []}和{"a": 1} - 列表类型的顺序不同, 如:
[1, 2, 3]和[3, 2, 1]
这些差异需要视情况而定,有些场景下列表的顺序差异就代表两者不同,但是在这里列表的顺序差异是可以忽略不计的。
因此,在对比的时候需要将两个结构体进行泛化,才能准确地对比两个结构体是否相同,下面就用一段 python 代码来实现这个功能:
def normalize_json(obj: Any) -> Any:
"""递归地规范化 JSON 对象,使其可以进行顺序无关的比较
Args:
obj: 要规范化的对象,可以是字典、列表或其他 JSON 支持的类型
Returns:
规范化后的对象
"""
if isinstance(obj, dict):
# 如果字典为空,返回 None
if not obj:
return None
normalized = [(k, normalize_json(v)) for k, v in obj.items()]
normalized = [(k, v) for k, v in normalized if v is not None]
return sorted(normalized) if normalized else None
elif isinstance(obj, list):
if not obj:
return None
normalized = [normalize_json(x) for x in obj]
normalized = [x for x in normalized if x is not None]
return sorted(normalized) if normalized else None
else:
return obj
def stringify_json(obj: Any) -> Any:
"""将规范化的对象转换回 JSON 对象
Args:
obj: 规范化后的对象,可能是元组列表(字典)或排序后的列表
Returns:
转换回原始 JSON 结构的对象,如果输入为 None,返回空字典或空列表
"""
if obj is None:
return {}
elif isinstance(obj, list):
if obj and isinstance(obj[0], tuple):
return {k: stringify_json(v) for k, v in obj}
return [stringify_json(x) for x in obj]
elif isinstance(obj, tuple):
return {obj[0]: stringify_json(obj[1])}
else:
return obj
# 测试
json1 = '{"a": [2, 1], "b": {"x": 1, "y": 2}}'
json2 = '{"a": [1, 2], "b": {"y": 2, "x": 1}, "c": []}'
normalized1 = normalize_json(json.loads(json1))
normalized2 = normalize_json(json.loads(json2))
print(normalized1) # [('a', [1, 2]), ('b', [('x', 1), ('y', 2)])]
print(normalized2) # [('a', [1, 2]), ('b', [('x', 1), ('y', 2)])]
restored1 = stringify_json(normalized1)
restored2 = stringify_json(normalized2)
print(json.dumps(restored1)) # {"a": [1, 2], "b": {"x": 1, "y": 2}}
print(json.dumps(restored2)) # {"a": [1, 2], "b": {"x": 1, "y": 2}}
可以看到原本两个不相同的JSON字符串,json1 和 json2,经过 normalize_json 函数处理后,得到的结果是相同的,因此可以认为这两个JSON字符串是相同的。
normalize_json 函数的实现思路是:
- 对 key 进行排序,达到让 JSON 归一化的目的。想要排序那么格式一定是需要数组类型,因此这里对所有的 kv 递归处理为(key, value)的元组格式,存放为一个数组,再使用 key 进行排序。
- 过滤掉其中的空值: 空值对比较没有意义。
总结 #
本文介绍了如何在 Kubernetes 中使用 grpcreplay 实现 gRPC 流量镜像。通过 sidecar 容器的方式,我们可以将 grpcreplay 部署在旧服务和新服务的旁边,从而实现流量的复制和对比。这种方式的好处在于:
- 不需要修改应用代码;
- 相比于代理的方式,不会影响应用的性能;
- 可以方便的对比新旧服务的响应内容的差异;
如果当前环境中已经有 Istio 这种 service mesh 的话,那么可以考虑使用 Virtual Service 的 mirror 配置来快速实现流量复制,另外再加上一个请求和响应的记录器,就可以实现流量的复制和对比。