
Kafka 和 MongoDB 是目前使用比较广泛的消息队列和数据库,在之前的很长时间里对这两个软件系统的理解都停留在概念和使用上,直到最近遇到一个“诡异”的问题,已有的经验和调试方法无法定位时,最终尝试了下抓包分析才最终定位到问题的根源。
问题描述: 使用 sarama 编写了一个 kafka 消费者组,这里不同寻常的地方在于:手动提交 + 批量消费。遇到的问题:某些分区消费进度无法成功提交,但是消息是消费成功的。出现这种情况的分区没有规律,触发 rebalance 后 “故障分区” 有概率会发生变化。
分析/定位:这里很明显的问题在于手动提交 offset 为什么不成功?从实现来说,提交 offset 的逻辑跟分区没有关系是一致,那这种不确定性故障时从哪儿来的?而且还和 rebalance 相关。 梳理下 kafka 客户端消费提交涉及到的操作:
Fetch,OffsetCommit, 但是消费是正常的,那么只需要抓包分析OffsetCommit就可以知道 offset 提交存在什么问题。结果: 通过抓包一切都明朗了:出现问题的分区同时有多个 OffsetCommit 请求,且其中有的请求提交的 offset 一致停留在一个 “旧的” 位置,不会更新,这样就缩小了范围:程序提交 offset 逻辑异常。
KAFKA 协议 #
Kafka 协议是基于 TCP/IP 协议的二进制协议。其结构组成如下:
struct RequestOrResponse {
RequestResponseHeader requestResponseHeader; // uint32 messageLength;
SpecificRequestOrResponseHeader body; // 格式取决于具体的请求和响应,比如:RequestV1Header
}
struct RequestV1Header {
int16 apiKey;
int16 apiVersion;
int32 correlationId;
string clientId;
}
协议结构 #
二进制协议的结构如下:
Request V1 Header:
0 1 2 3 4
0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
| message length (total message size) |
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
| request api key | request api version |
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
| correlation_id |
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
| client id length N | |
| client_id 占用 N 空间的,这里不确定具体的长度 |
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
| request extend header |
| .................................... |
| .................................... |
| request extend header |
| .................................... |
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
| 字段 | 描述 |
|---|---|
| message length | INT32, 消息长度,包括所有字段,不包括消息长度本身。 |
| request api key | INT16 请求的 API 键,用于标识请求的类型。 |
| request api version | INT16 请求的 API 版本,用于标识请求的版本。 |
| correlation_id | INT32 关联 ID,用于标识请求和响应之间的关系。 |
| client id | NULLABLE_STRING, 客户端 ID, 是一个 NULLABLE_STRING |
NULLABLE_STRING Represents a sequence of characters or null.
For non-null strings, first the length N is given as an INT16. Then N bytes follow which are the UTF-8 encoding of the character sequence.
A null value is encoded with length of -1 and there are no following bytes.
Request V2 Header:
0 1 2 3 4
0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
| message length (total message size) |
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
| request api key | request api version |
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
| correlation_id |
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
| client id length N | |
| client_id 占用 N 空间的,这里不确定具体的长度 |
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
| _tagged_fields (仅为说明该值传输,占用空间不确定) |
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
| request extend header |
| .................................... |
| .................................... |
| request extend header |
| .................................... |
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
Response V0 Header:
0 1 2 3 4
0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
| message length (total message size) |
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
| correlation_id |
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
| 字段 | 描述 |
|---|---|
| correlation_id | UINT32 关联 ID,用于标识请求和响应之间的关系。 |
Response V1 Header:
0 1 2 3 4
0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
| message length (total message size) |
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
| correlation_id |
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
| _tagged_fields (仅为说明该值传输,占用空间不确定) |
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
这里 request 和 reponse header 分别有两个版本,且相当于前一个版本,后者增加了一个 _tagged_fields 字段,其格式为:
| The number of tagged fields | Field 1 Tag | Field 1 Length | Field 1 Data | Field 2 Tag | Field 2 Length | Field 2 Data | … |
|---|---|---|---|---|---|---|---|
| UNSIGNED_VARINT | UNSIGNED_VARINT | UNSIGNED_VARINT | <field 1 type> | UNSIGNED_VARINT | UNSIGNED_VARINT | <field 2 type> | … |
UNSIGNED_VARINT 是一种变长的无符号整数编码方式,参考 google protobuf varint 和 zig-zag 编码。如果是 tagCount = 0,那么这里只需要使用一个字节表示 0x00。
API 请求和响应举例 #
其中 request 和 response header 格式取决于请求和响应的类型。比如 ApiVersion(18) 请求有 5 个版本,如下:
| API Version | Based Request Header Version | fields |
|---|---|---|
| 0 | 1 | - |
| 1 | 1 | - |
| 2 | 1 | - |
| 3 | 2 | client_software_name(COMPACT_STRING); client_software_version(COMPACT_STRING); _tagged_fileds |
| 4 | 2 | client_software_name(COMPACT_STRING); client_software_version(COMPACT_STRING); _tagged_fileds |
响应有 4 个版本,如下:
| API Version | Based Response Header Version | fields |
|---|---|---|
| 0 | 0 | {error_code, api_keys[{api_key,min_version,max_version}]} |
| 1 | 0 | {error_code, api_keys[{api_key,min_version,max_version}], throttle_time_ms} |
| 2 | 0 | {error_code, api_keys[{api_key,min_version,max_version}], throttle_time_ms} |
| 3 | 0 | {error_code, api_keys[{api_key,min_version,max_version,_tagged_fields}], throttle_time_ms, _tagged_fields} |
更多的请求和响应 header 格式参考:API Keys
协议抓包分析 #
下面使用 wireshark 抓包并结合前面提到的协议实际分析下 Kafka 协议的交互过程。启动一个 kafka 客户端:
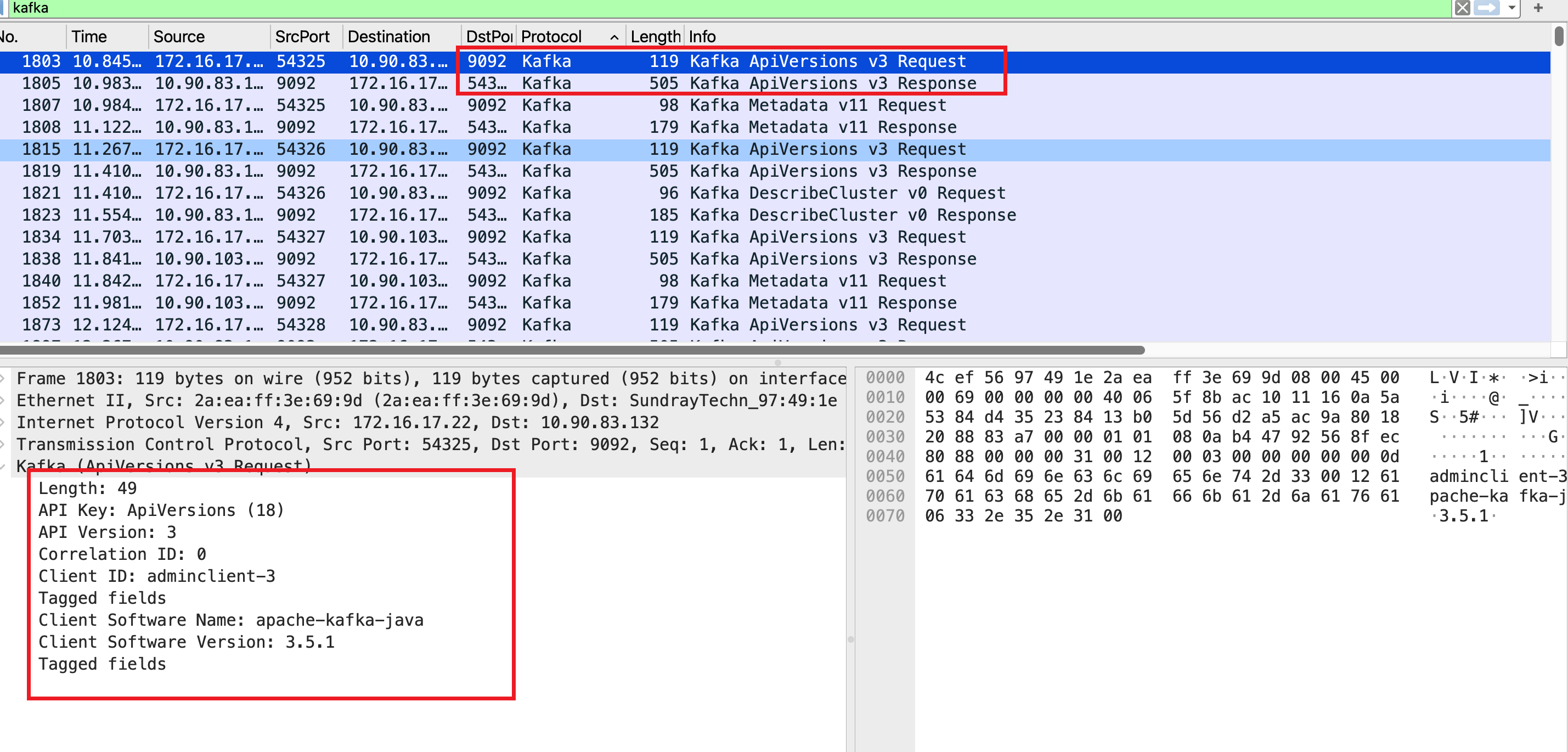
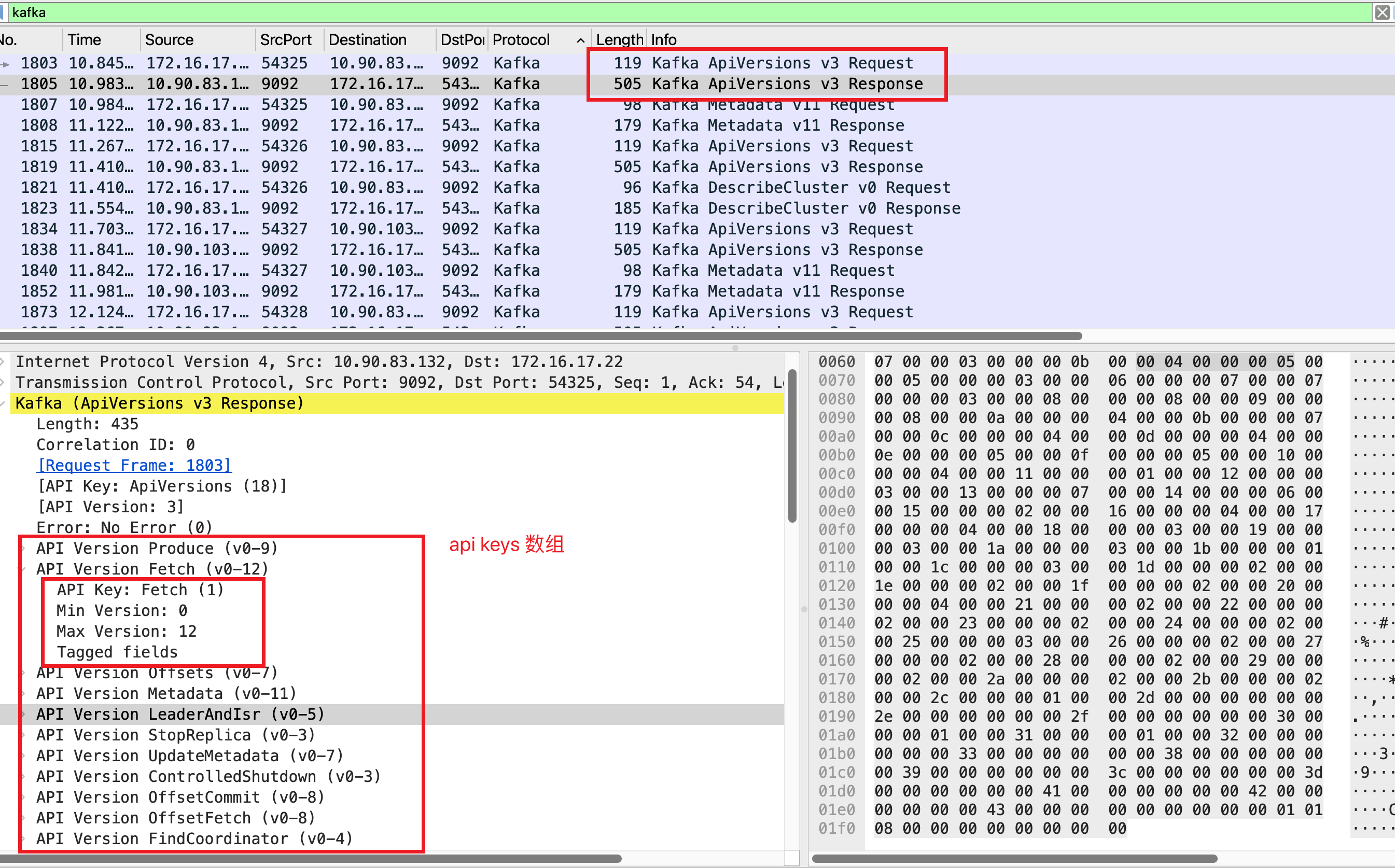
从图中能看到由于 wireshark 解析已经足够好了,所以看到的 kafka 协议字段已经可读性非常高了,直接就能和协议文档一一对应起来。唯一需要注意的就是 kafka 协议的编码需要根据文档和字段类型进行解析,比如 NullableString 类型的字段需要先解析长度,然后再解析字符串; VARINT 遵循了变长的 zig-zag 编码,参考 Google Protocol Buffers
Zig-zag 编码解释:https://gist.github.com/mfuerstenau/ba870a29e16536fdbaba
小结 #
为了支持协议的向后兼容性,Kafka API 提供了版本化语义 和 ApiVersions API 来动态协商客户端和服务器通信协议(版本)。客户端连接到服务器之后需要请求服务端支持的 API 版本范围,从中选一个两边都支持的版本。在发送请求时,客户端携带 请求API 的版本,服务器默认相同版本的响应格式返回,如果客户端携带了不支持的版本,服务器会响应 UNSUPPORTED_VERSION(35) 以提示客户端调整版本。
协议中定义了 API Keys 枚举,用来说明服务器支持的 API 清单,每个 API 都有唯一的标识ID,客户端和服务器通过这个 ID 对应特定的功能,也用来确定具体的请求和响应格式。
Kafka 协议采用了二进制编码,为此协议中约定了一些基础类型,如:BOOLEAN,INT8, INT16, INT32, INT64, UINT, VARINT, VARLONG, UUID, STRING, COMPACT_STRING 等等。
MongoDB 协议 #
MongoDB 协议是一个简单的基于 socket 的请求响应协议。客户端通过一个常规的 TCP/IP 套接字与数据库服务器进行通信,服务器默认端口为 27017,协议采用了小端字节序。
标准消息头 #
通常而言,每条消息都是有一个标准消息头和紧跟着的数据构成,标准消息头格式如下:
0 1 2 3 4
0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
| message length (total message size) |
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
| requestID (identifier for this message) |
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
| responseTo (requestID from the origin request) |
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
| opcode (message type) |
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
其中 OpCode 的取值有如下几种:
注意随着 MongoDB 版本的升级,MongoDB 已经使用 OP_MSG 操作码来统一请求和响应格式。
| OpCode | 值 | 描述 |
|---|---|---|
| OP_COMPRESSED | 2011 | 使用压缩来来包装其他操作码 |
| OP_MSG | 2013 | 使用标准格式发送消息。用于客户端请求和数据库回复。 |
| OP_REPLY | 1 | 响应消息。自 MongoDB 5.0 弃用,5.1 删除 |
| OP_UPDATE | 2001 | 更新消息。自 MongoDB 5.0 弃用,5.1 删除 |
| OP_INSERT | 2002 | 插入消息。自 MongoDB 5.0 弃用,5.1 删除 |
| RESERVED | 2003 | 以前用于 OP_GET_BY_OID |
| OP_QUERY | 2004 | 查询消息。自 MongoDB 5.0 弃用,5.1 删除 |
| OP_GET_MORE | 2005 | 获取更多消息。自 MongoDB 5.0 弃用,5.1 删除 |
| OP_DELETE | 2006 | 删除消息。自 MongoDB 5.0 弃用,5.1 删除 |
| OP_KILL_CURSORS | 2007 | 杀死游标消息。自 MongoDB 5.0 弃用,5.1 删除 |
OP_COMPRESSED 消息格式 #
任何操作码都可以使用 OP_COMPRESSED 来包装,OP_COMPRESSED 消息格式如下:
struct OP_COMPRESSED {
MsgHeader header; // 标准消息头
int32 originalOpcode; // 原始 opcode
int32 uncompressedSize; // 未压缩消息大小
uint8 compressorId; // 压缩器(算法)的标识
char *compressedMessage; // 压缩后的消息,不包括标准消息头
}
compressorId 的取值有如下几种:
| compressorId | 值 | 描述 |
|---|---|---|
| 0 | noop | 不压缩 |
| 1 | snappy | snappy 压缩算法 |
| 2 | zlib | zlib 压缩算法 |
| 3 | zstd | zstd 压缩算法 |
| 4-255 | 保留 | 保留 |
OP_MSG 消息格式 #
OP_MSG 是一种可以扩展的消息格式,用于客户端请求和服务器响应。其格式如下:
struct OP_MSG {
MsgHeader header; // 标准消息头
uint32 flagBits; // 标志位
Sections[] sections; // 数据段
optional<uint32> checksum; // 校验和 CRC-32C
}
FlagBits
FlagsBits 是一个 32 位的无符号整数,用来说明 OP_MSG 的格式和行为。前 16 位是必要的,并且如果有未知位设置,解析器必须要抛出错误。后16位是可选的,解析器必须忽略任何未知位设置,代理和消息转发器必须清除任何未知位设置。
| bit位 | 字段 | 请求 | 响应 | 描述 |
|---|---|---|---|---|
| 0 | checksumPresent | ✅ | ✅ | 表示消息是否包含校验和 |
| 1 | moreToCome | ✅ | ✅ | 表示是否有更多数据段。另一条消息将紧随此消息之后,无需接收方采取进一步行动。接收方在收到 moreToCome 设置为 0 的消息之前, 不得发送其他消息,否则发送可能会阻塞,从而导致死锁。带有 moreToCome 的请求 位设置不会收到回复。回复只会包含此 响应设置了 exhaustAllowed 位的请求而设置。 |
| 16 | exhaustAllowed | ✅ | - | 客户端已准备好使用 moreToCome 位对此请求进行多次回复。除非请求中设置了此位,否则服务器永远不会生成设置了 moreToCome 位的回复。 |
Sections
OP_MSG 消息包含一个或者多个部分(section),每个部分都以一个kind 字节开头,kind 用来指示类型。kind 之后的字节构成该部分的载荷。
| kind | 描述 |
|---|---|
| 0 | Body, body section 被编码为单个 BSON 对象;BSON 对象的字节大小在 section 开始位置(64位) |
| 1 | Document Sequence, 支持传输多个文档,优化批量操作。 其基本结构是 |
| 2 | 仅内部使用 |
Body 类型常用于标准的请求和响应体。
CheckSum
每条消息都可以附带 CRC-32C 校验和,用于验证消息的完整性(除 checksum 自身)。
协议抓包分析 #
下面用 wireshark 抓包并结合前面提到的协议实际分析下 MongoDB 协议的交互过程。使用 mongosh 连接到 MongoDB 数据库,执行一条查询所有db的命令:
Using MongoDB: 7.0.2
Using Mongosh: 2.3.2
$ mongosh
> show databases
抓包结果如下:
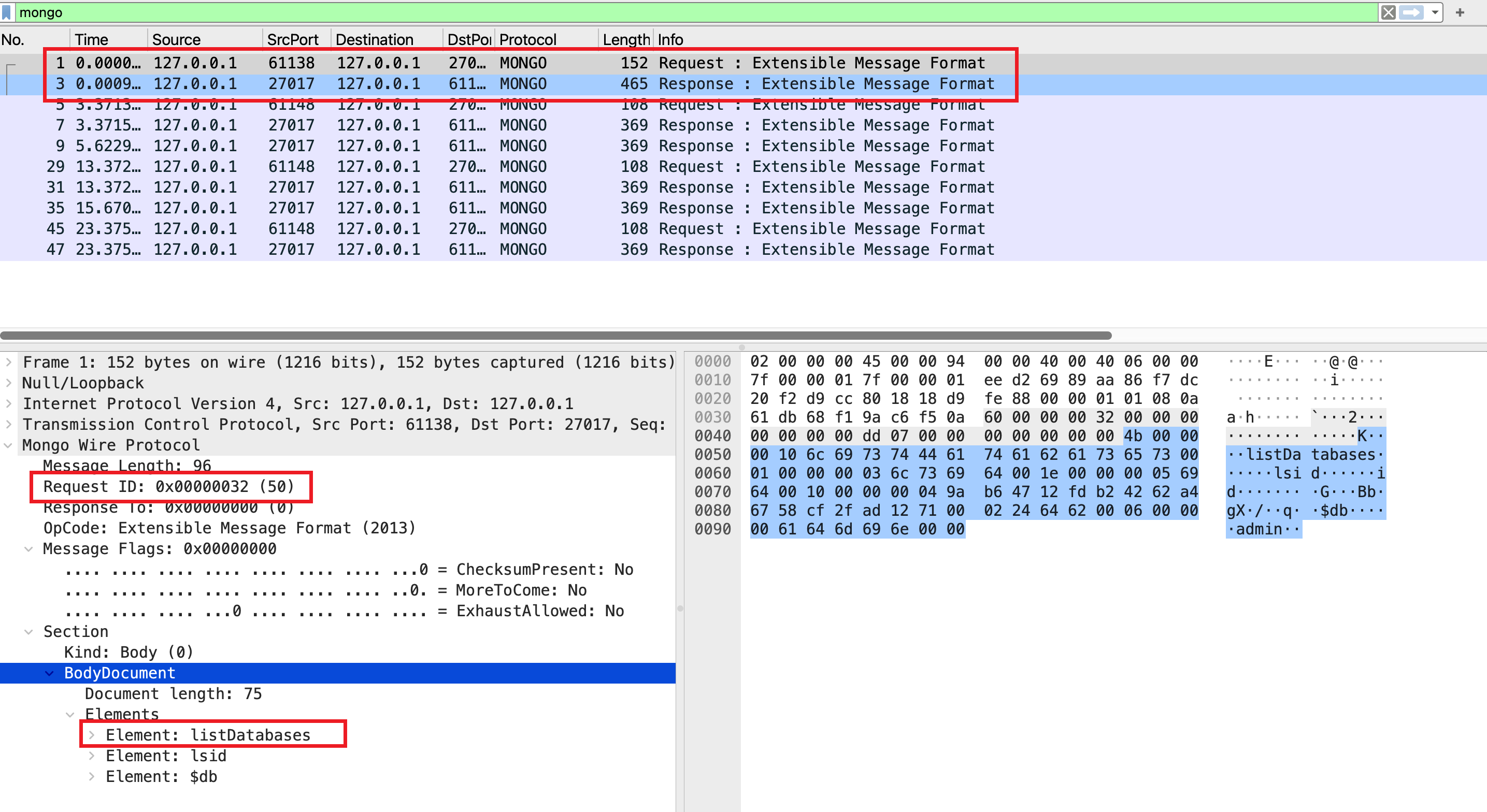
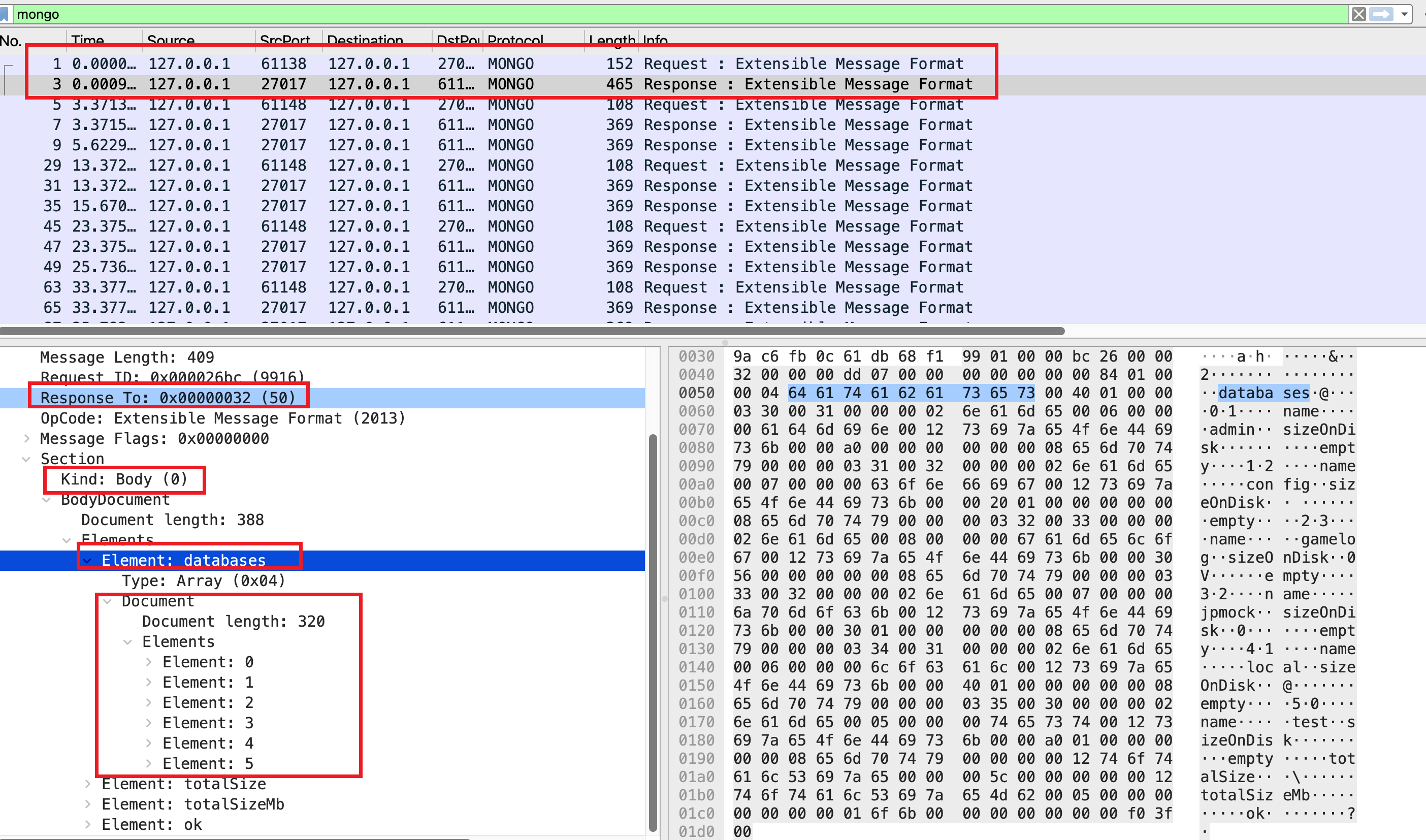
wireshark 可以清晰的看到 show databases 命令的请求和响应体。都包含了标准消息头(message length, requestID, responseTo, opcode)。响应中的 reponseTo 值等于对应请求的 requestID,而请求中的 reponseTo 值为 0,这也是区分请求和响应的方法。
在 OP_MSG(opcode = 2013, 也就是 Extensible Message Format) 消息体中包含了 flagBits, sections 等字段,而 checksum 由于 flagBits 中没有设置,所以没有包含。
掌握了这些基本概念后,我们可以简单的手搓一个脚本用来解析 MongoDB 协议( wireshark 毕竟看起来不那么直观)。核心解析代码如下:
def parse_op_msg(self, payload):
"""解析 OP_MSG 消息格式
OP_MSG 格式 (MongoDB 3.6+):
struct {
MsgHeader header; // 标准消息头, 16 字节
uint32 flagBits; // 标志位
// 接下来是一个或多个部分 (sections)
// 每个部分以一个字节的类型标识开始
// 类型 0: 正文部分 (body section)
// 类型 1: 文档序列部分 (document sequence)
}
"""
if len(payload) < 20: # 头部 16 字节 + 标志位 4 字节
return None
try:
# 解析标志位
flag_bits = struct.unpack("<I", payload[16:20])[0]
flags = []
for bit, name in OP_MSG_FLAGS.items():
if flag_bits & (1 << bit):
flags.append(name)
result = {
"flags": flags,
"sections": []
}
# 解析部分 (sections)
offset = 20 # 跳过头部和标志位
# 读取部分类型
kind = payload[offset]
offset += 1
if kind == 0: # Body kind
section = {
"kind": "body",
"document": None,
"error": None
}
doc = parse_body_kind(payload[offset:])
if doc:
section["document"] = doc
result["sections"].append(section)
offset = len(payload)
else: # documentSequence kind 和 其他,这里暂不考虑
section = {
"kind": f"unknown({kind})",
"error": "未知的部分类型"
}
result["sections"].append(section)
return result
except Exception as e:
raise Exception(f"解析 OP_MSG 消息时出错: {e}")
return None
def parse_body_kind(payload) -> dict:
"""
解析 OP_MSG 消息体中的 body 类的 section:
8byte 的 sectionMessageLength
剩余都是 body 的 section
"""
if len(payload) < 4:
return None
try:
# 这里通过 bson.decode_document 整个 payload 就是 bson 序列化后的结构。
# length (4 bytes) + payload (length-4, bytes)
doc = bson.decode_document(payload, 0)
return doc
except Exception as e:
print(f"解析 OP_MSG 消息体中的 body 类的 section 时出错: {e}")
return None
展示结果如下:
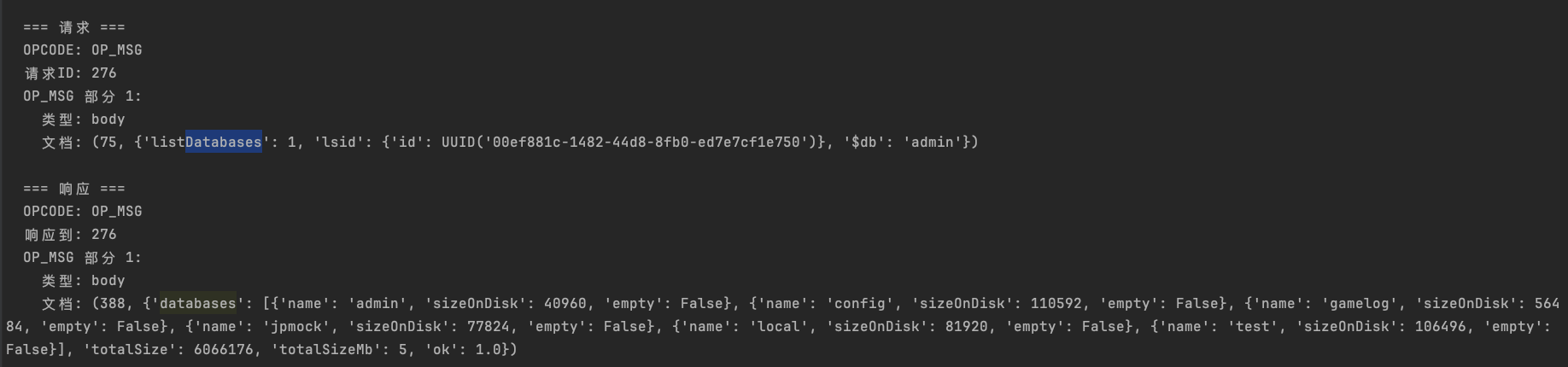
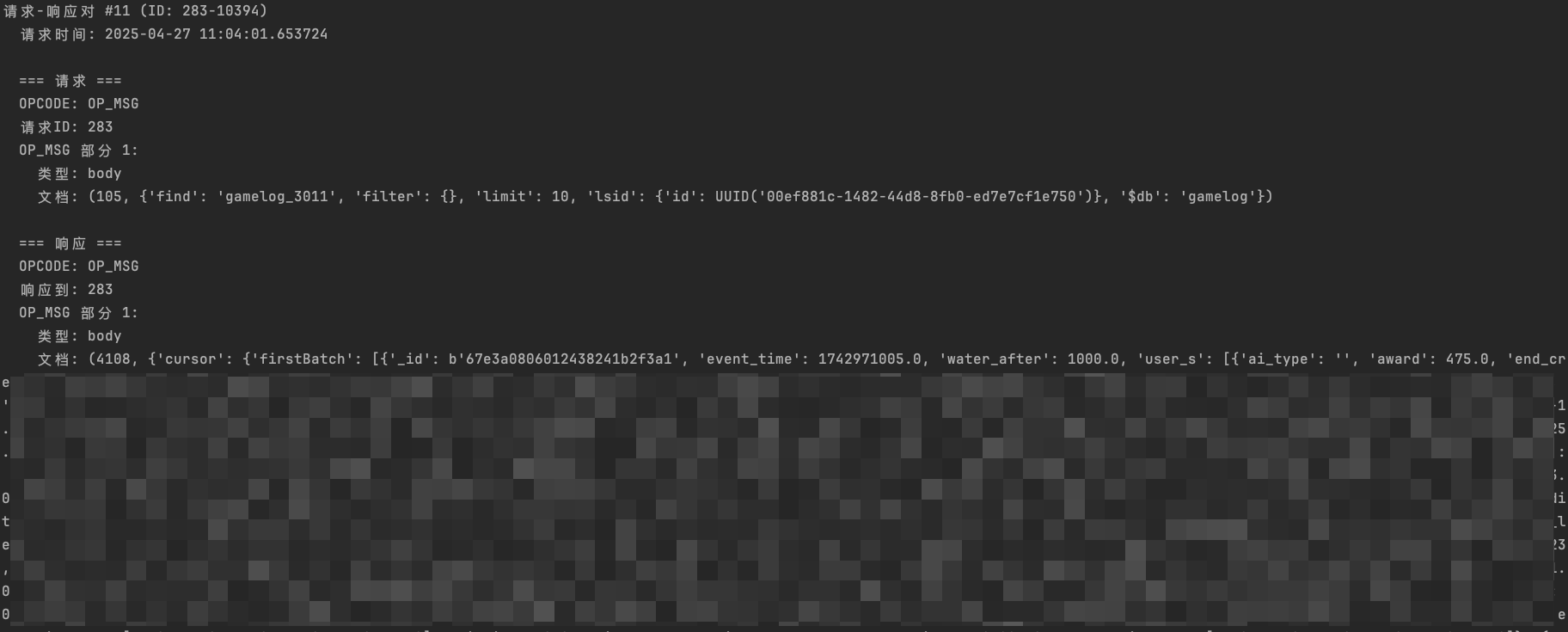
小结 #
MongoDB 协议采用了小端字节序,并且使用了标准的 TCP/IP 套接字进行通信;客户端和服务器通过一个常规的 TCP/IP 套接字进行通信,服务器默认端口为 27017。
随着 MongoDB 版本的升级,MongoDB 已经使用 OP_MSG 操作码来统一请求和响应格式。在 OP_MSG 中 Section 采用 BSON 编码,这样非常灵活,如果 API 功能进行了调整(新增/调整了字段,那么是可以不需要调整协议,而只用调整功能即可)。
要进一步深入的话可以再实现一个简单的 MongoDB 客户端,或者结合某个特定的客户端实现代码来深入了解 mongodb 协议的交互过程。当然这里还没有深究 show databases 这种命令的具体内容,有兴趣可以继续研究下 MongoDB specification。
总结 #
任何 C/S 模式的软件系统都可以自定义自己的 “协议”,而这些协议的模式大同小异,简单的可以直接使用文本协议实现如 memcached, 复杂的则可以完全自定义自己的二进制协议,如 kafka 和 mongodb, 更进一步它们甚至有自己独一套的编码协议,但是不管怎么样一套协议也无非就是:确定传输协议 + 设计应用协议 + 采用什么编码。
掌握这些协议的设计思路和理念之后,下一步就可以去深入了解软件整体的 API 功能设计,这样会帮助我们更深入服务侧的逻辑实现,加深对软件系统的理解。